")
Posted on July 12, 2019
| Back to Showreel
Learning to Self-Correct from Demonstrations
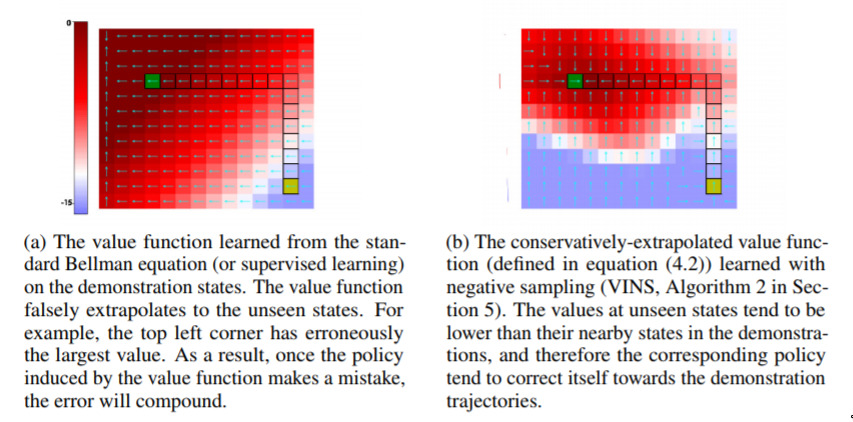
This one is a bit technical, but the main idea here is that they are able to “moderate” how reinforcement-learning networks will extrapolate, when they are learning by example. An analogy would be that, when you watch someone take a sip from a cup, you assume “brilliant, I can drink from any thing that I am holding”, and then you try and drink from a pen, or a book, or such. Here, they introduce the idea that perhaps you should act a bit conservatively in areas where you are unsure, such as holding new things.
