")
Deep learning showreel!
This list is no-longer updated.
-
RigNet - Neural Rigging for Articulated Characters — May 1, 2020
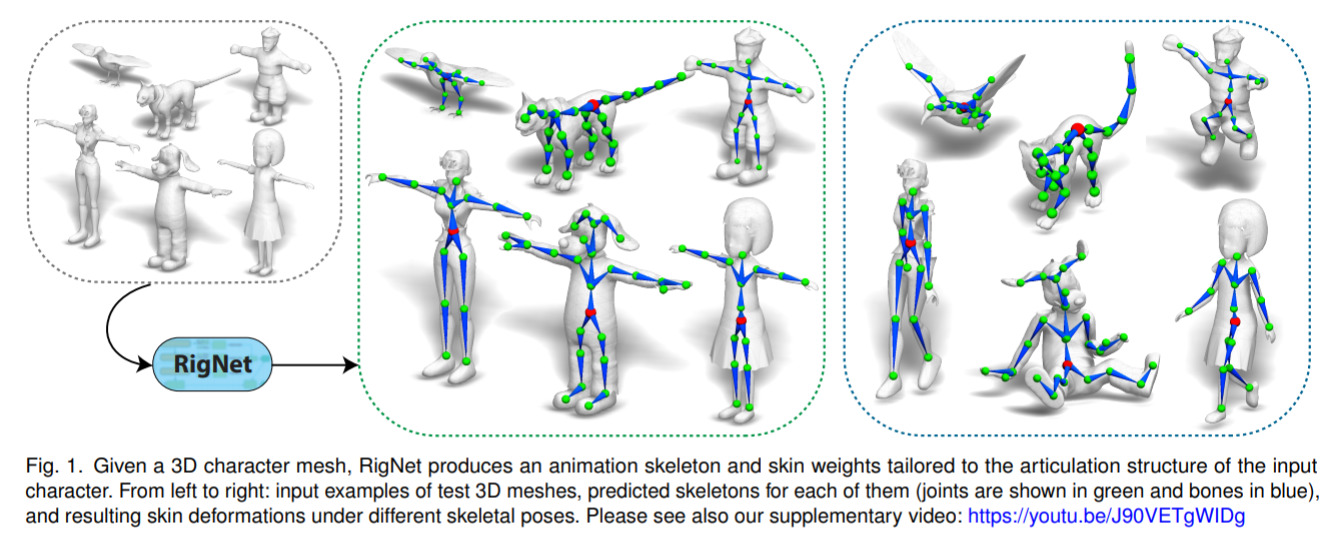
This is a truly awesome result (be sure to check out the video) which can take in a 3D model, then compute a “rigging” so that it can be animated; i.e. walking, dancing, jumping, etc.
Super useful for animation and games, and just plain fun!
-
Investigating Transferability in Pretrained Language Models — April 30, 2020
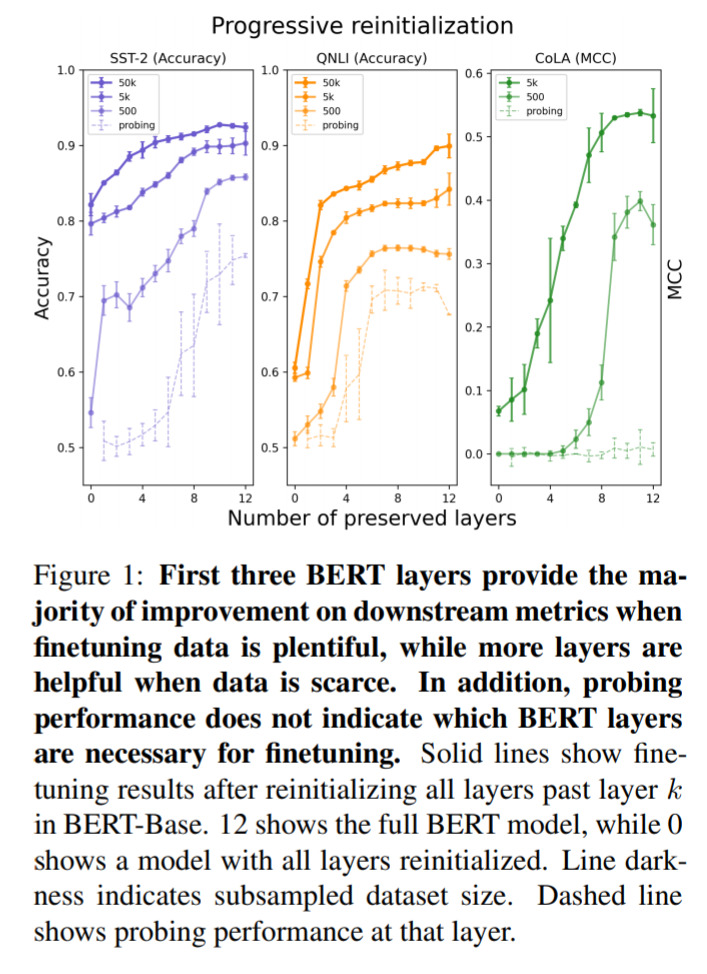
This is mostly a useful and interesting technical result around what is the best way to do transfer-learning when working with NLP models. The point is, in different data size regimes, you should do different things, to achieve the best results.
-
Consistent Video Depth Estimation — April 30, 2020

This is an interesting one. The idea is that we want to predict a “consistent” depth over the frames of a video. If we naively treat each frame as an independent image, we get very bad consistency; i.e. if we’re moving the camera across a scene; the depth changes wildly.
In the paper they introduce a technique to solve this problem, which then allows for very cool applications! Check out the videos.
-
Editing in Style - Uncovering the Local Semantics of GANs — April 29, 2020

Generative adversarial networks (GANs) are hugely popular for generating fake images. But a key topic is fine-grained editing and adjusting. I.e. you can generate a random person, but can you generate a random smiling person? To what degree can we edit these visual features of people?
This paper presents a mechanism by using reference images and regions and transferring them onto the generated images. Neat! And useful.
-
MakeItTalk - Speaker-Aware Talking Head Animation — April 27, 2020
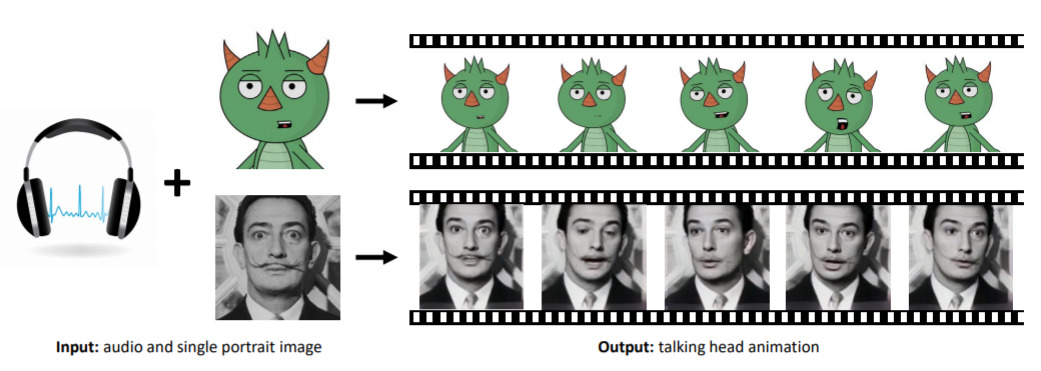
A simple dream realised. We take an audoclip, and a still image, and animate the image as if it’s speaking the audio. Check out the video.
Adobe is investing heavily in this kind of connection between audio and images; they also did some early work on “audio inpainting”. Expect some cool products from them in the future.
-
Graph2Plan - Learning Floorplan Generation from Layout Graphs — April 27, 2020
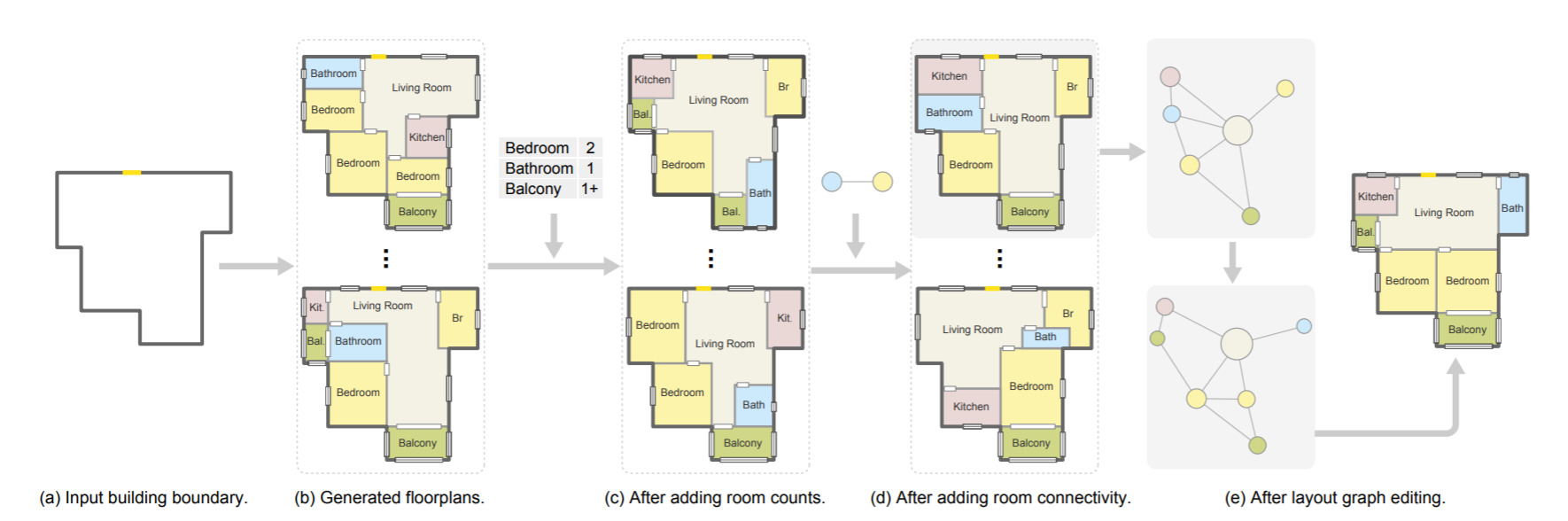
I have a soft-spot for AI-generated architecture; and this one is interesting because it gives the user some high-level control on what the generation does. I.e. you can control the number of rooms, how they connect, and roughly the layout.
This kind of thing, built well into modern CAD tools, would be really cool!
-
Quantum Gradient Algorithm for General Polynomials — April 23, 2020
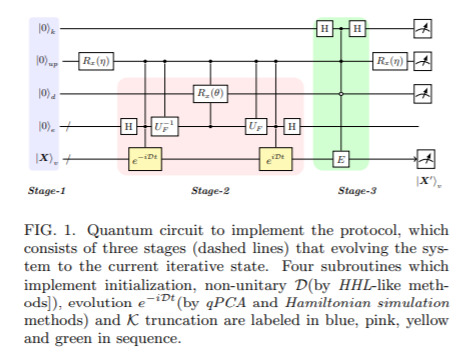
The idea here is that, in principle, if you have a lot of parameters in your function, then the time to compute the entire gradient w.r.t. all the parameters will scale like the number of parameters. This is bad when you have billions of parameters; so mostly in optimisation we focus on stochastic gradient descent; i.e. just looking at a small number of parameters at any one time.
Here, the idea is that we could use quantum computers to do the full computation significantly faster. In this, and algorithm is introduced that in fact achieves this, for general polynomials (perhaps a step towards achieving it for full neural networks).
-
ViBE - A Tool for Measuring and Mitigating Bias in Image Datasets — April 16, 2020

This is an interesting tool that helps formalise how to think about bias in your datasets. It allows you to gain formalised insights (i.e. “you don’t have enough data from this country”) and then generate concrete actions. It’s early days, but tools like this will be very useful as the field matures.
-
Efficient State Read-out for Quantum Machine Learning Algorithms — April 14, 2020
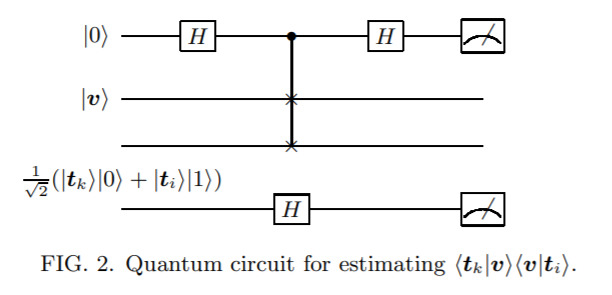
One annoying technical issue that occurs in quantum machine learning is that, maybe it’s possible to run a quantum algorithm that performs better than a classical one, but you lose all the speedup when you simply try and read the answer out! So frustrating.
This paper addresses this problem.
-
3D Photography using Context-aware Layered Depth Inpainting — April 9, 2020

A nice technique to make a cool little animation from a 2D image. Check out the video here.
-
Typilus: Neural Type Hints — April 6, 2020
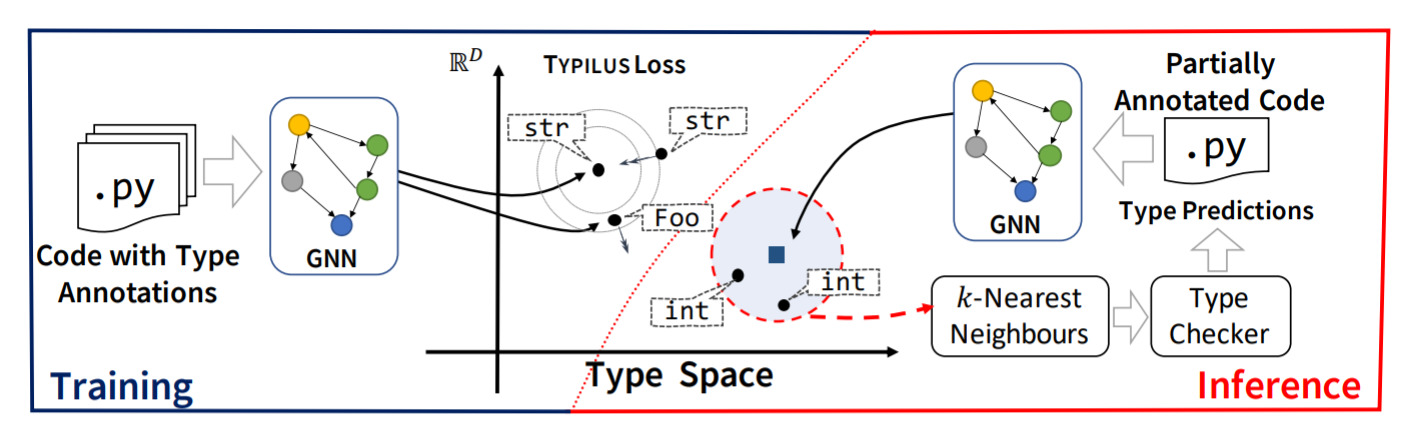
This is probably a niche one; but interesting to see someone tackling this problem. The idea is that estimating types for Python functions is hard; so perhaps a neural network can be used to do it. Turns out, you can go some way with this idea!
-
Learning Generative Models of Shape Handles — April 6, 2020

You can imagine that manipulating, arbitrarily, objects in 3D is very hard. How to change a chair in a “structured” way? This paper presents a really cool way of manipulating such shapes; with pretty cool results!
-
GANSpace - Discovering Interpretable GAN Controls — April 6, 2020

A theme that comes up again and again; this is another great piece of work in this vein; how can we control the generated images from GANs?
This is really a very important topic, in part because it will empower users to interact with these tools.
-
Adaptive Fractional Dilated Convolution Network for Image Aesthetics Assessment — April 6, 2020
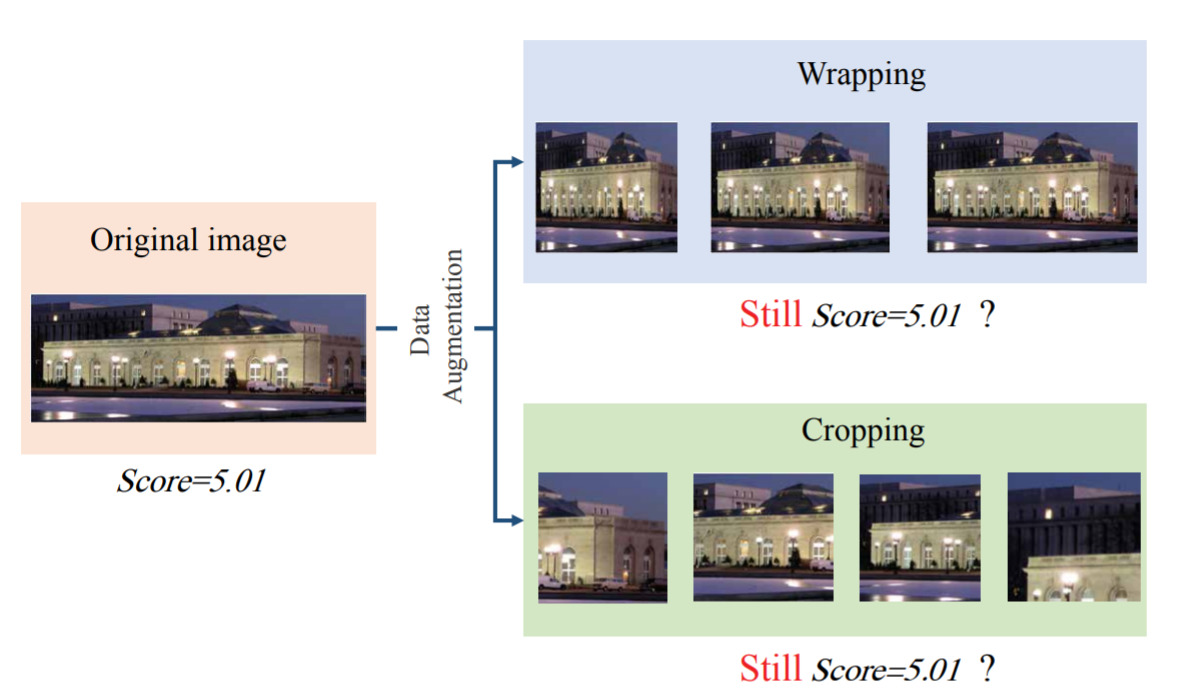
I like this idea because it reminds me of Christopher Alexander’s ideas of the objective beauty of photos and the idea of considering which photo has more “life”.
It’s also useful for judging the quality of generative images; which is the most asthetic?
Interesting work.
-
Generating Rationales in Visual Question Answering — April 4, 2020

A nice result in the field of explainability; we can give visual explanations to visual questions, to help explain our reasoning. Very useful.
-
Learning to See Through Obstructions — April 2, 2020

Very simple one; a computer-vision algorithm to just remove general visual obstructions (like rain, glare, fences) from photos! Handy.
-
Sign Language Translation With Transformers — April 1, 2020
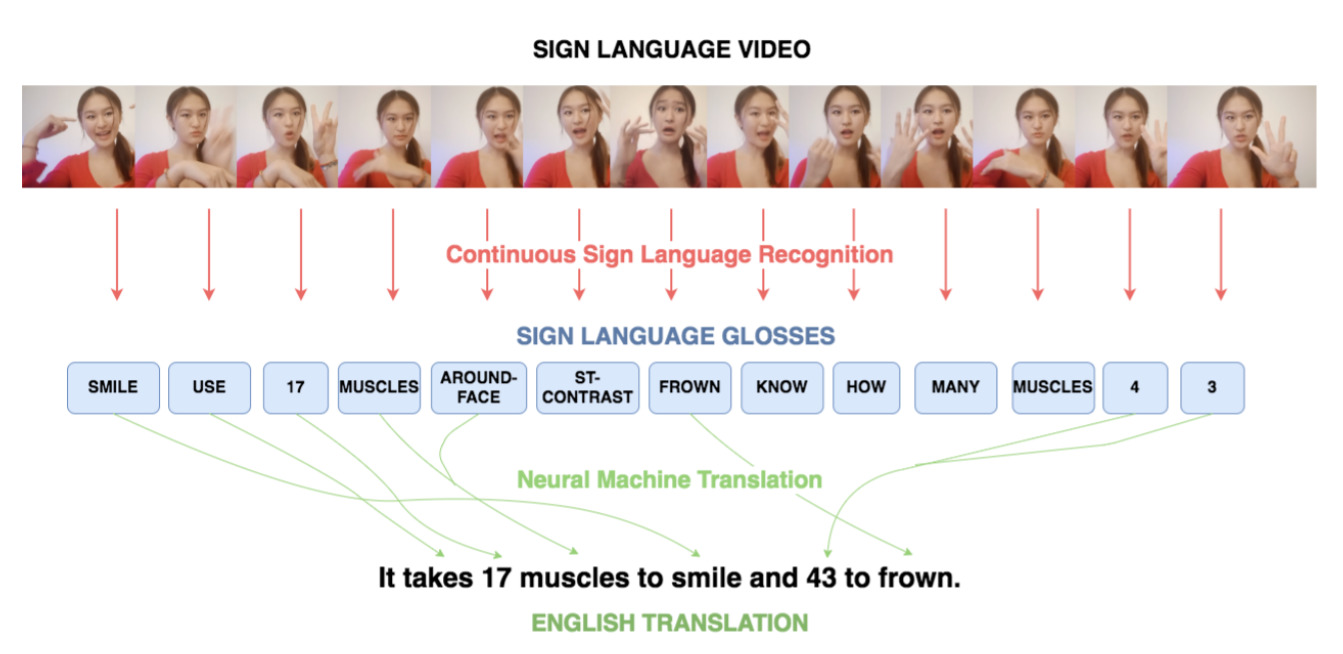
Nice technique to watch sign language videos and interpreting them.
-
Design of Variational Autoencoder-based Rhythm Generator as a DAW plugin — April 1, 2020
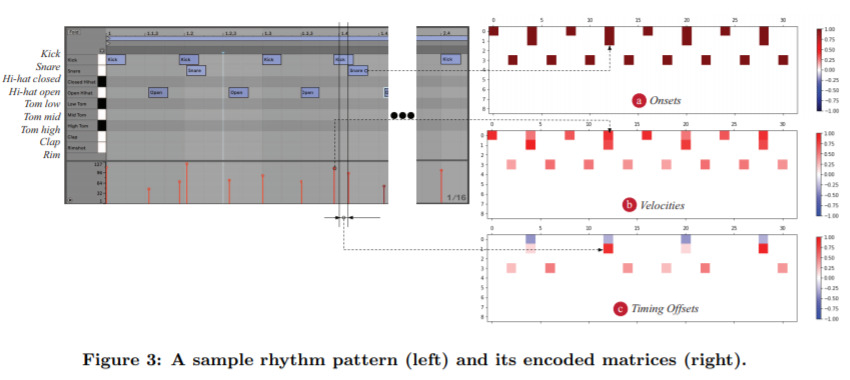
I like this because it’s a kind of “applied” example of generative AI; here they build a generative music AI into Abelton Live. Check out the code here.
-
Convolutional Neural Networks for Image-based Corn Kernel Detection and Counting — March 26, 2020

I like this because it’s just a simple idea, implemented well, that is probably of use to someone!
-
Deformable Style Transfer — March 24, 2020
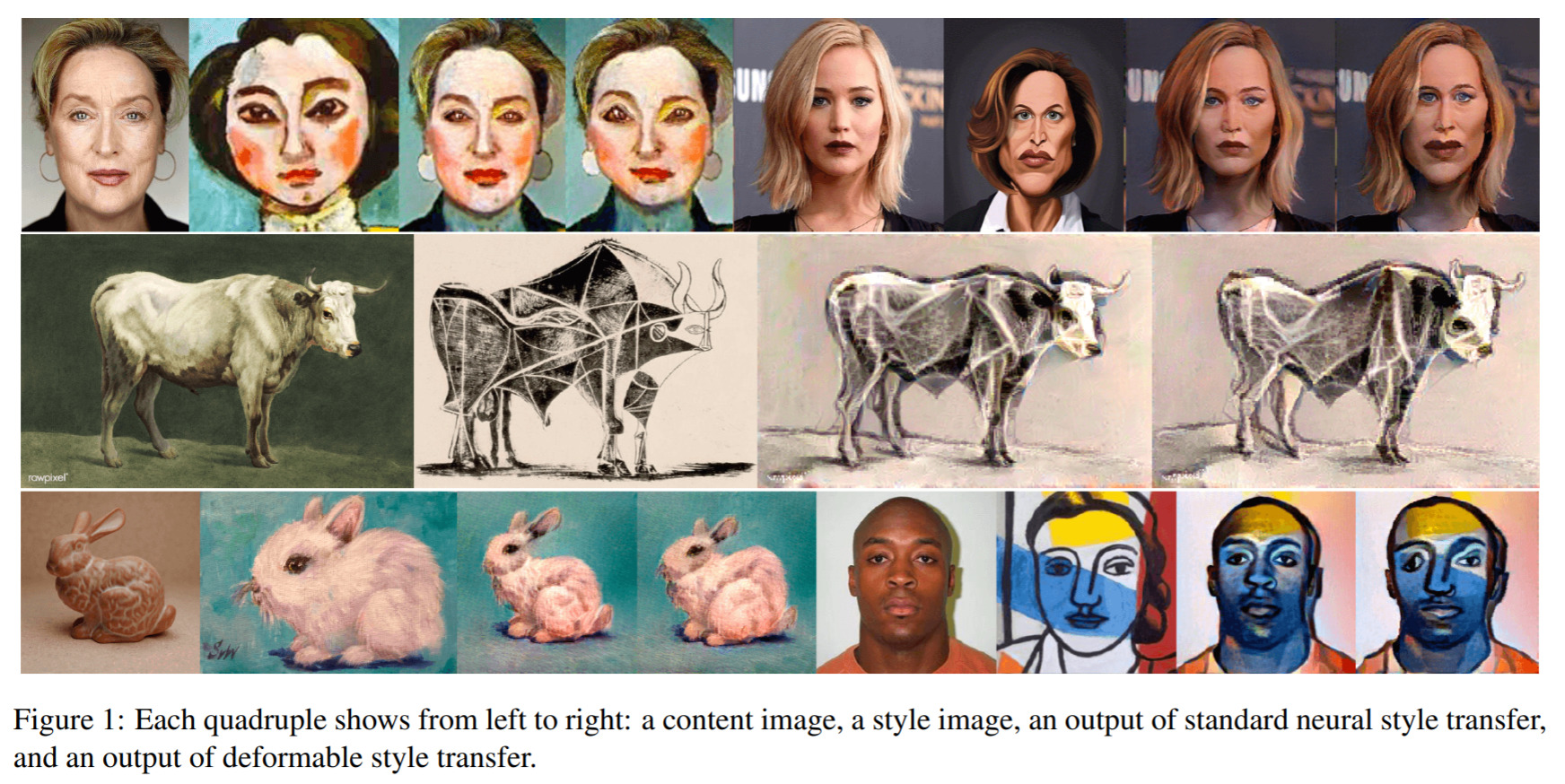
I really think this is quite amazing. The results of the style transfer on these phtoso are simply the best I’ve ever seen. Incredible!
-
Learning Object Permanence from Video — March 23, 2020
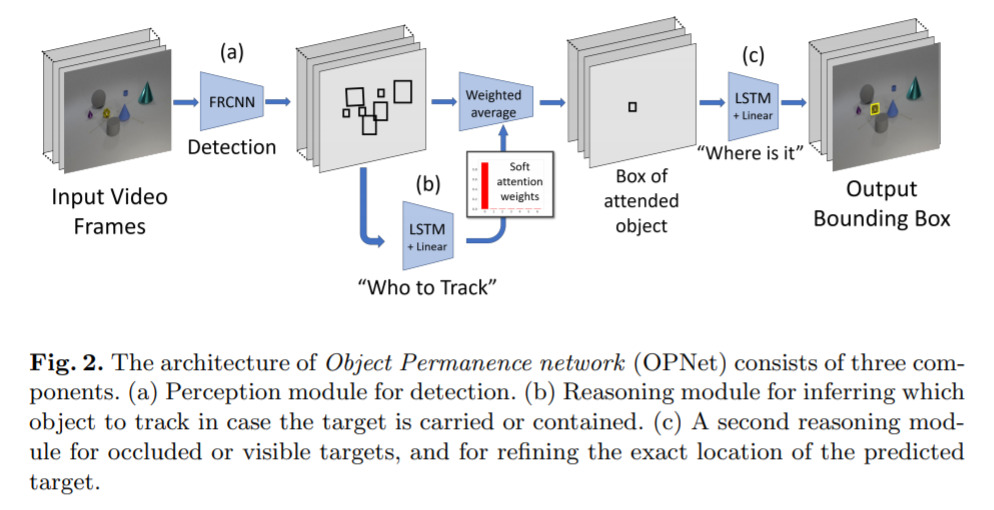
A classic thing that babies learn is that objects don’t physically disappear when they go behind things. Neural networks have struggled with this problem. This paper goes some way to addressing this issue.
-
3D-CariGAN - An End-to-End Solution to 3D Caricature Generation from Face Photos — March 15, 2020

I think this one is just plain funny. An end-to-end approach for generating a 3d physical caricature from a photo. Cool!
-
Towards Photo-Realistic Virtual Try-On by Adaptively Generating and Preserving Image Content — March 12, 2020

This is a nice step towards high-quality “virtual try-on”; i.e. the idea that you can take an image of a person, and a product photo, and then see what it would look like to “try” that item on!
-
TensorFlow Quantum — March 6, 2020
This has been coming for a while; it’s a start of building some kind of quantum capability into the TensorFlow library. It’s not perfect, but it’s a start.
-
Privacy-preserving Learning via Deep Net Pruning — March 4, 2020

This is interesting paper in that it shows how “differential privacy” can be related to network pruning. Differential privacy is the idea that we can hide individual datapoints by adding noise. This is useful if, say, working on medical data where we want to not reveal individual patients.
The trade-off is between how much worse does the network get as we increase the privacy (i.e. make it harder to recover individual datapoints). This paper links this idea with the idea of pruning neural networks in a precise way.
-
Learning to Transfer Texture from Clothing Images to 3D Humans — March 4, 2020

A good step on the way to full virtual try-on would be just to dress 3D models with product photos. This paper does just that!
-
Inverse Graphics GAN - Learning to Generate 3D Shapes from Unstructured 2D Data — February 28, 2020

This is a cool idea done well. The point is, you can imagine it’s very hard to generate an arbitrary 3D model for a given image. This does a pretty good job!
-
Sketch-to-Art - Synthesizing Stylized Art Images From Sketches — February 26, 2020
This is just a nice result. I really like the outputs that are generated. You can play around with this idea over here.
-
Wait, I'm Still Talking — February 22, 2020
This is a nice result that estimates the best time to respond to a series of chat messages. In a idealised world maybe every chat message is atomic; but in a real chat situation, people can ramble over several messages until they get to their central question.
-
AutoFoley - Artificial Synthesis of Synchronized Sound Tracks for Silent Videos with Deep Learning — February 21, 2020
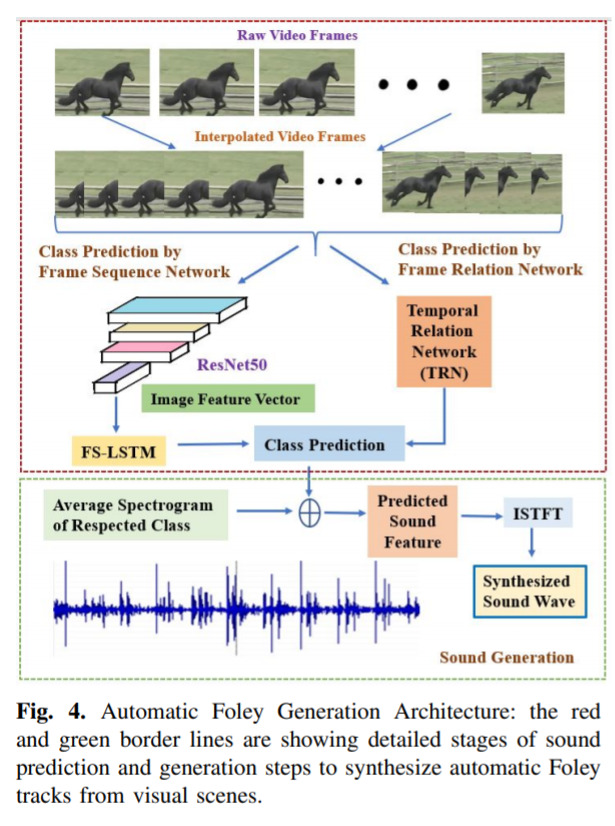
This is a cool idea; given some video, generate the sound. The paper is worth a glance for the photo they show of a foley studio! I never knew they looked so cool!
-
Seeing the World in a Bag of Chips — January 14, 2020

Is the world reflected in a bag of chips? Yes! Turns out, using a neural network, if you want to know whats going on around you; you can just take a photo (with depth information) of the chip packet and figure it out!
-
Learning to Zoom-in via Learning to Zoom-out — January 8, 2020

This paper tackles the now-standard problem of “enhancing” an image; i.e. being able to look into any region of an image in greater detail. The trick here is that they utilise the idea of learning to zoom out to also learn to zoom in. The results are very good!
-
Painting Many Pasts - Synthesizing Time Lapse Videos of Paintings — January 4, 2020

This is a cute one. The idea is simply to see if it’s’ possible to show the “painting progression” of a finished painting. I.e. what might be (photographs) of the steps of making this painting?
I think this is a really neat idea; would love to see some artists try and replicate the steps, to confirm that they (somewhat) match reality!
-
Generating Object Stamps — January 1, 2020

Here we have the idea of, given some background image, can we fill it with arbitrary objects so that it looks realistic? Here they show that they are able to solve this problem very nicely, by filling a diverse range of wildlife scenes with animals!
-
FaceShifter - Towards High Fidelity And Occlusion Aware Face Swapping — December 31, 2019

I think the results of this one are amazing. They get this to work using a multi-staged network approach; i.e. a few different networks performing different functions, such as one to learn “attributes”, and another to refine the output of the main one. Lots to learn from this!
-
SketchTransfer - A Challenging New Task for Exploring Detail-Invariance and the Abstractions Learned by Deep Networks — December 25, 2019
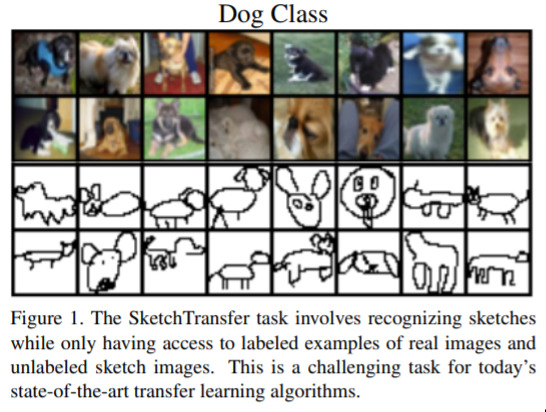
This isn’t a network itself; it’s a dataset and a proposed task. The idea of this dataset is that there is definitely a similarity between sketches of real objects, and photos of those objects; but, neural networks aren’t great at knowing this abstraction, yet. I.e. If I have an object-classifier, it can’t very well classify sketches. We’ll see how people progress towards this problem via this dataset!
-
ConvPoseCNN - Dense Convolutional 6D Object Pose Estimation — December 16, 2019
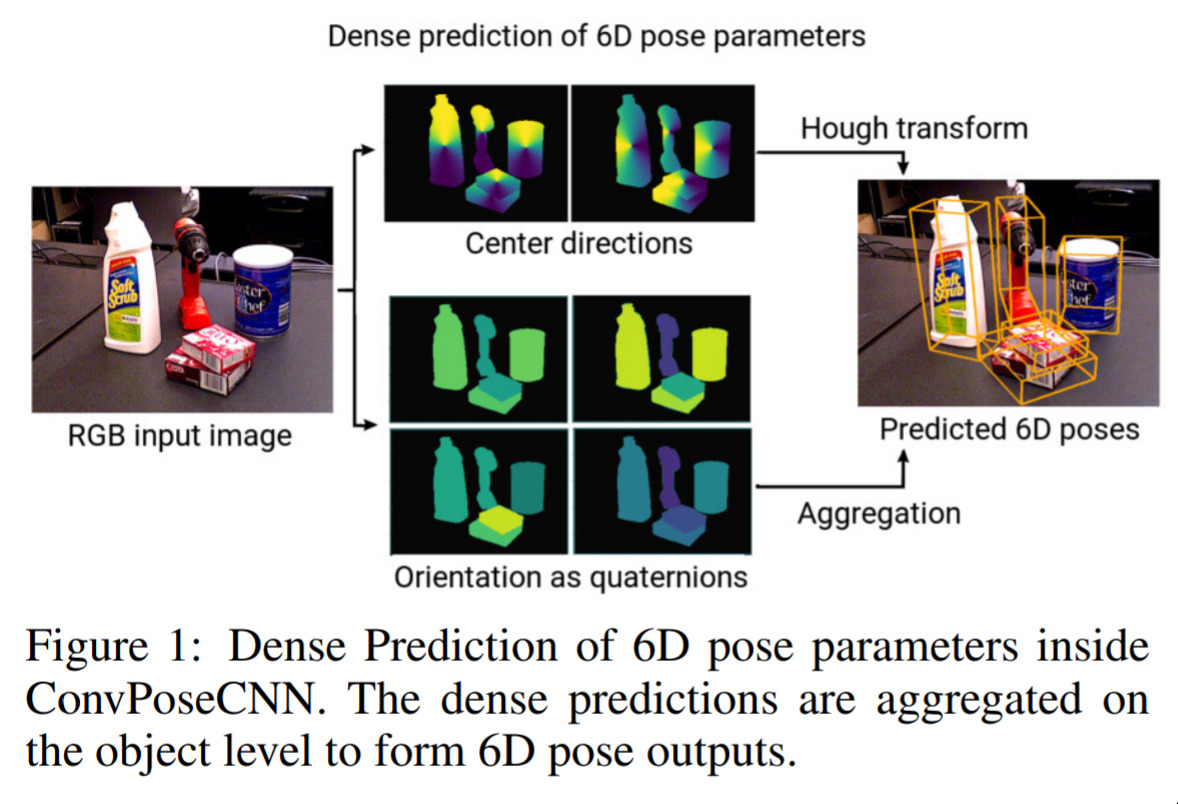
Imagine, if you will, that you are lying in a liquid in some particular pose. Then, this network can take the pose you are in, and construct a mesh (i.e. a piece of 3D furniture) that would support you exactly! Amazing!
-
Visual Interactive Comparison of Vector Embeddings — November 5, 2019
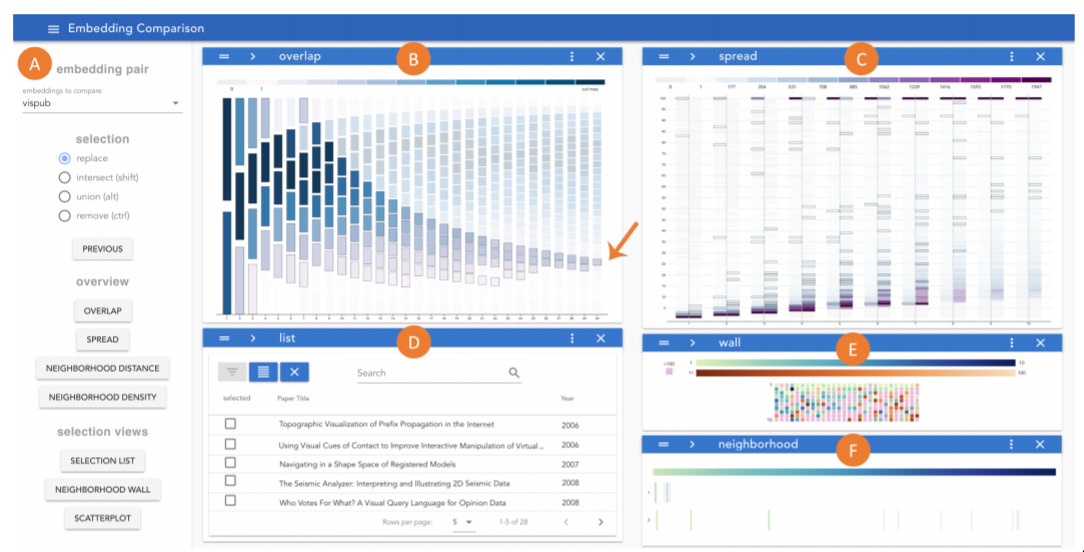
As we cover in the 6 week workshop, embeddings are the essence of deep learning. So any method to compare and understand them is going to be a big hit here.
As embeddings become more … embedded in all aspects of our AI piplines, tools like this will become increasingly important.
Furthermore, the idea of learning how to explore embedding spaces is also very valuable, and I think this is a useful step in that direction.
-
Satellite Pose Estimation Challenge — November 5, 2019

This one is neat because, at least to me, I didn’t even realise this could be a problem. But, it turns out that if you’re in the space business, you might have occasion to be interested in which way your satellite is facing, especially if it’s not responding to your commands any further.
In this work, they introduce a dataset, and competition metrics, and some baselines. Interesting problem!
-
Dancing to Music — November 5, 2019
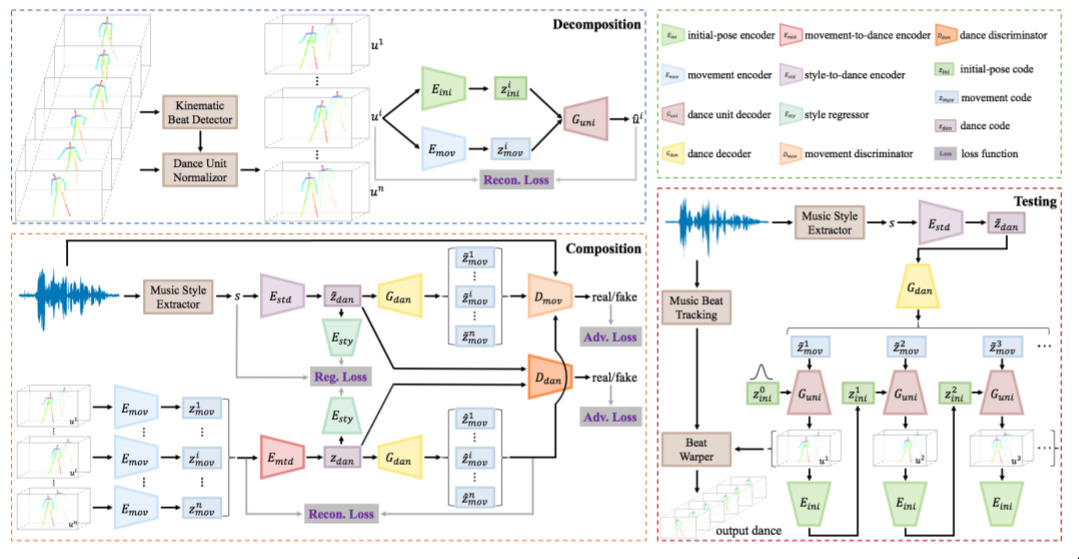
This is an idea that I worked on a long time ago. The idea is simple: Can we generate a dancing animation in response to music? Indeed, it’s possible.
Here, the contribution is around aligning movements to beats, and other bits of necessary busywork to decouple different musical elements so they can be used by the network.
You can see some generated videos over on their homepage.
-
What Does A Network Layer Hear — November 4, 2019
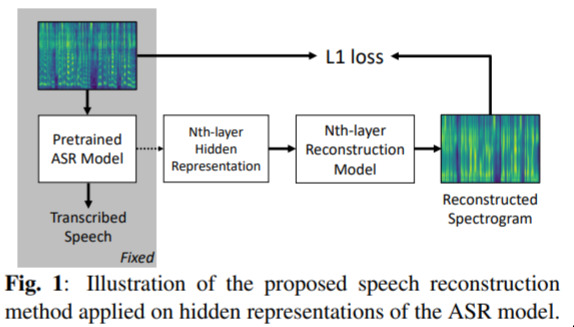
This is just a nice idea that I haven’t seen before. We’ve seen plenty of interpretation by visualisation, but nothing in terms of sound! Neat idea.
-
Making an Invisibility Cloak — October 31, 2019

This time it’s a jumper that fools person-detectors. In this work, they do a comparision of how their approach works on many different detectors, and introduce some metrics to contrast them.
-
Where Humans Live - The World Settlement Footprint — October 28, 2019
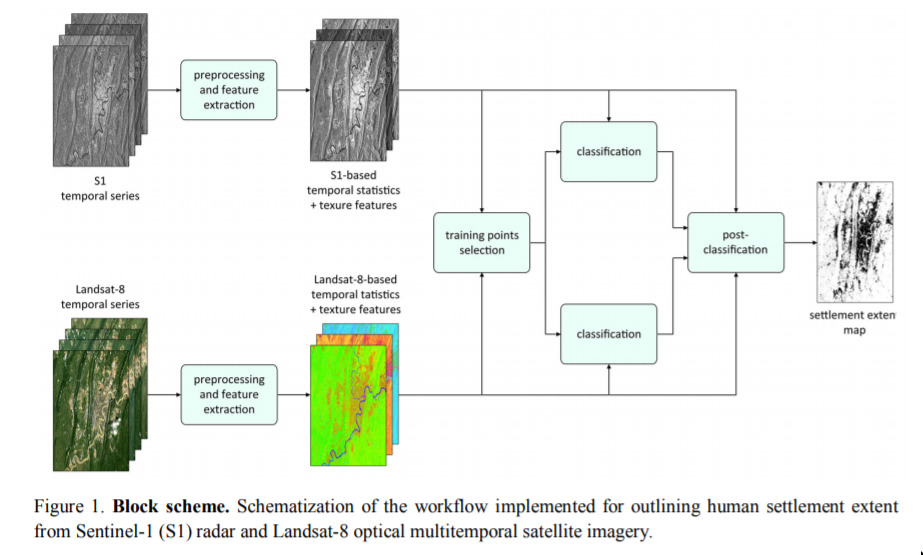
This is neat. Here, using deep learning, we’re able to compute this “global settlement map”, which would otherwise be totally unfeasible to obtain. A very nice real-world application.
-
Vision-Infused Deep Audio Inpainting — October 24, 2019
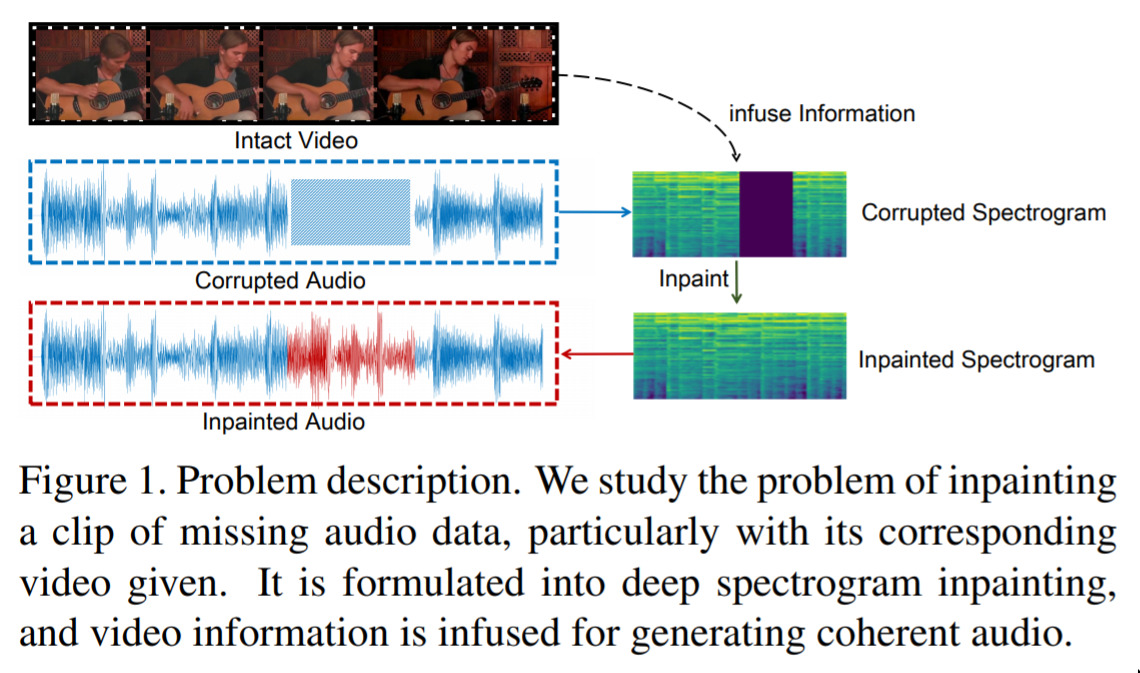
This is an interesting one. The idea is, we’ve lost some audio information in our video. We still have the video imagery, but a chunk of audio is gone. Can we use the remaining audio and the video, to reconstruct the missing part? The answer is yes. Neat!
-
Quantifying the Carbon Emissions of Machine Learning — October 21, 2019
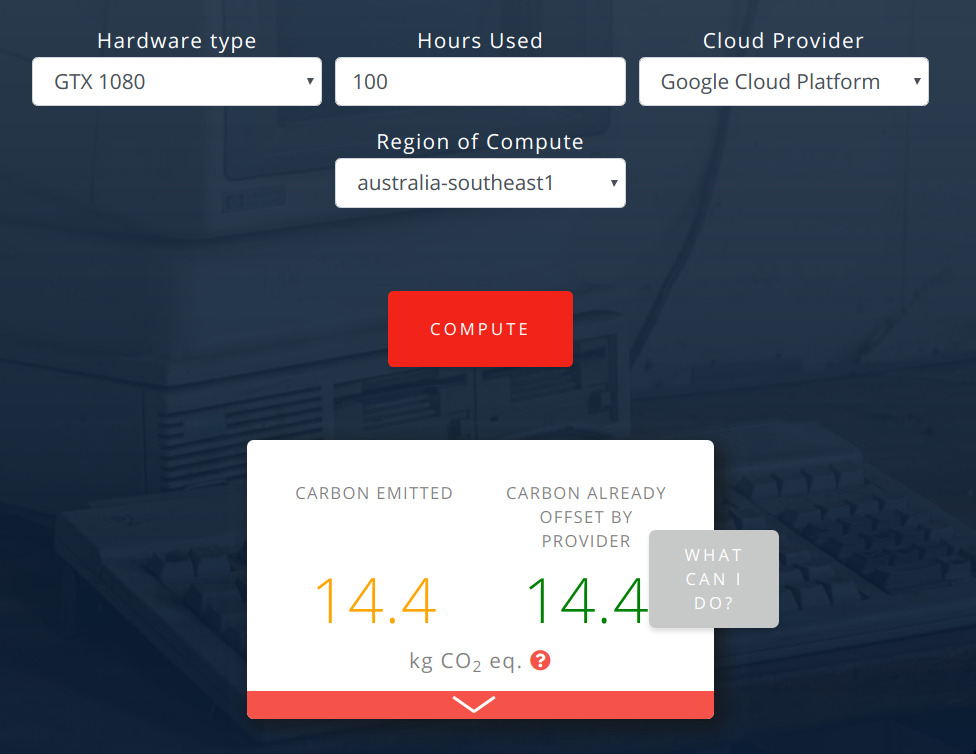
This is interesting. There’s no deep-learning here; it’s simply a tool, to compare and calculate how much carbon is emitted by various cloud providers and various GPUs. They also give advice on where else you might like to run your computation in order to save emissions.
Check out the website here.
-
Evading Real-Time Person Detectors by Adversarial T-shirt — October 18, 2019

There’s a lot of this kind of work going around at the moment. Building on a large body of “adversarial” attacks; the researchers demonstrate that it’s possible to design an image, that can be printed on a t-shirt, that fools person detectors.
A significant aspect of this work was to do with how the shirt moves as the body moves; i.e. the shirt should work in “real-time” (and it does!)
-
A Visual Analysis Tool to Explore Learned Representations in Transformers Models — October 11, 2019
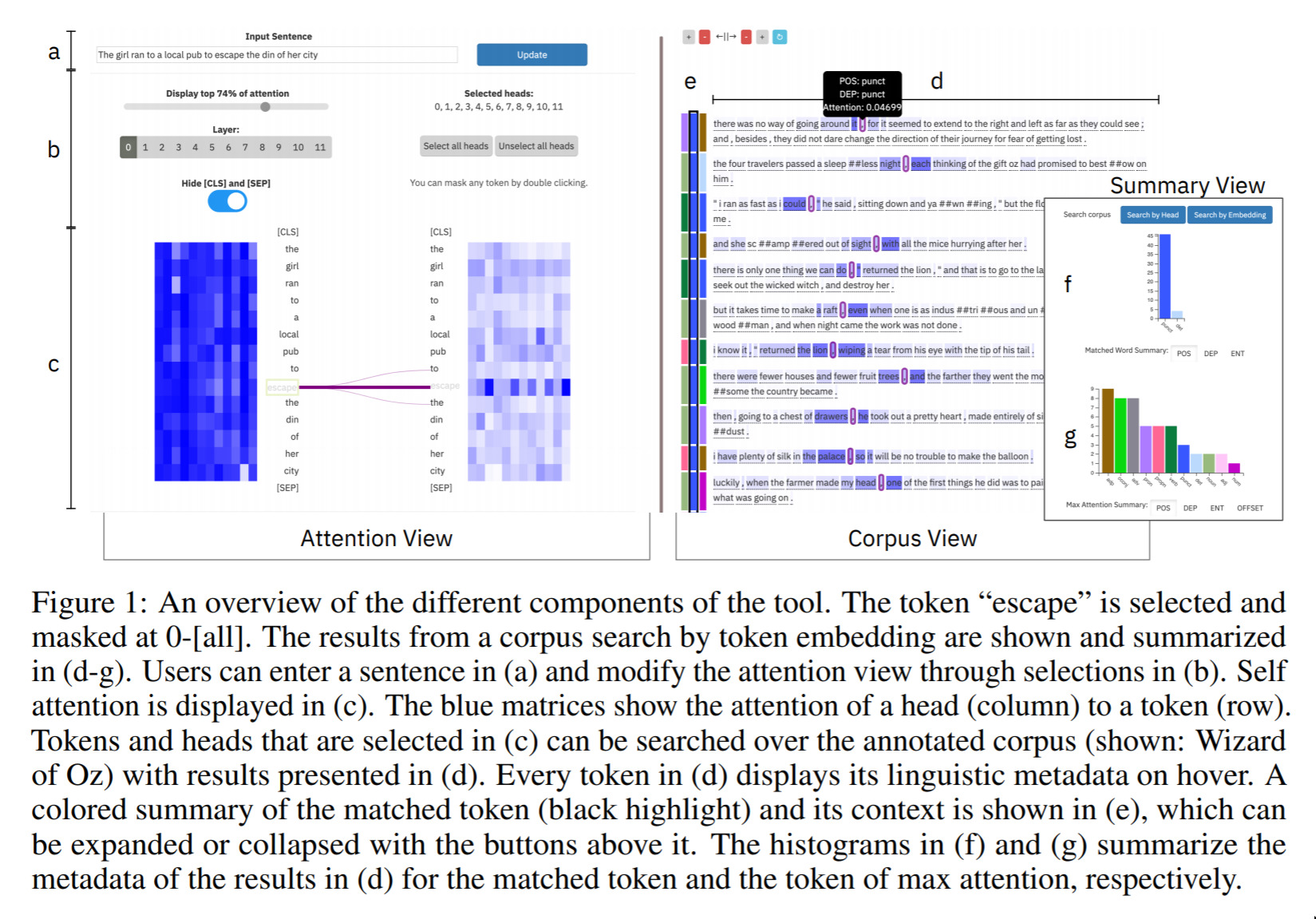
This is a nice exploration in the space of UX of AI, and the ability to understand what drives particular decisions and outcomes in a model. These days, big text models (a “Transformer” is a certain kind of text model) can be quite hard to understand.
The idea in this paper is to present a UI that can help with this! Nice development. We can expect to see much more of this kind of thing over the years.
-
Improving sample diversity of a pre-trained, class-conditional GAN by changing its class embeddings — October 10, 2019

This is mostly a technical result, but it’s really neat for the art applications. One of the problems with a lot of generative networks is that they lack “diversity”. This means that most of the time, the kinds of pictures they generate are mostly the same. This work address this problem, and even more impressively, it addresses it without the need to train the model again!
Very cool.
-
Dialog on a Canvas with a Machine — October 10, 2019

I really like this one. The main point here is a kind of collaboration between artists and some kind of generative network. I just love anything that brings humans and computers together in creative ways, and I think this is a great example.
-
A Generative Approach Towards Improved Robotic Detection of Marine Litter — October 10, 2019

This is another neat example of real-world AI. The point here is that working out what is trash or is otherwise a cool-looking sea animal or coral, is surprisingly hard.
One of the issues, as in many real-world situations, a lack of data.
But, by using some standard deep-learning approaches, namely by generating the images they need, they are able to get enough data to train a good model!
-
Adversarial Learning of Deepfakes in Accounting — October 9, 2019
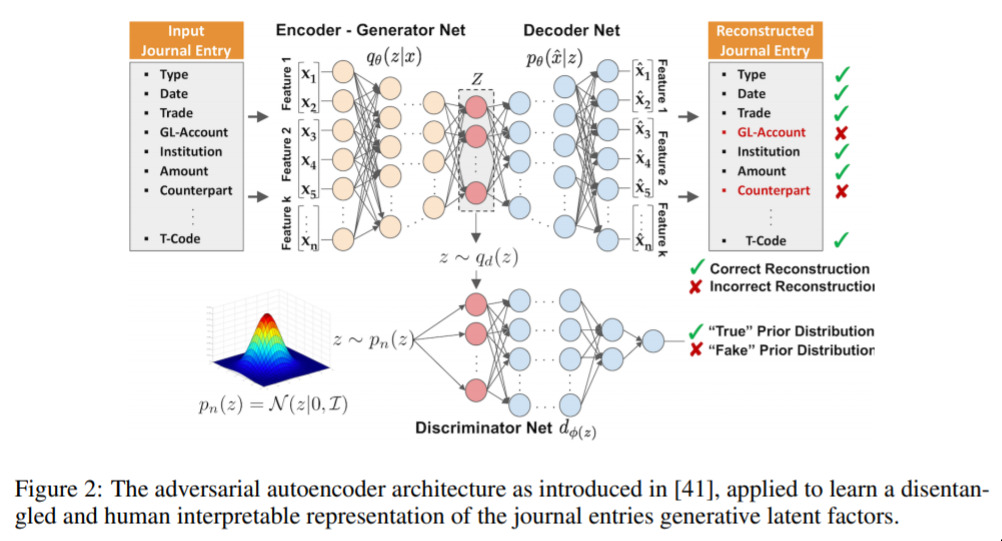
This is a neat one because it’s taking a cute idea and adapting it to a (very exciting!) business process. Namely, the financial auditing of a business.
The point here is that, by being able to generate accounting records, we might be able to mislead auditors; or at least some computer-based auditing assessments. The idea would be, by using this kind of approach, one could construct misleading journal entries.
I think it’s really interesting to see this kind of adversarial work move out of the domain of images and into the finance world! I’m sure we’ll see more of these kind of general adversarial networks over coming years!
-
Prose for a Painting — October 8, 2019

This is a cute, simple application. The idea is: How can we get cool Shakespeare-style descriptions of paintings? The answer: We can use language “style-transfer” to change a real poem about the painting into the Shakespearean style. That’s it!
-
Learn to explain efficiently via neural logic inductive learning — October 6, 2019
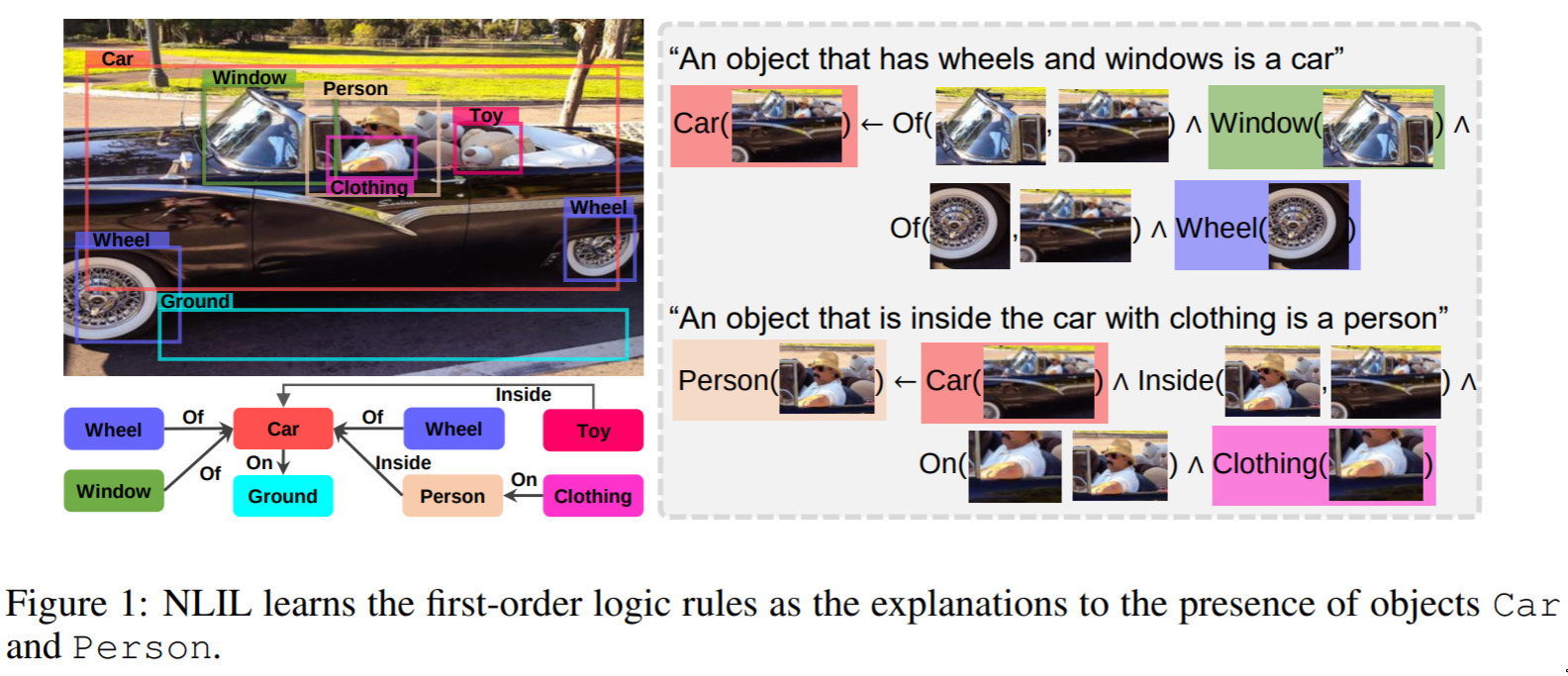
Along the lines of explainability, this is a fascinating and important step. Consider: How do you know that something is a car? What makes a person a person? This paper attempts to address this problem by a kind of “constructivist” approach. I.e. a car is a car because it has wheels.
I think this kind of logical reasoning will be increasingly important as models make richer decisions, and as we seek to get solid explanations from our models.
-
Addressing Failure Prediction by Learning Model Confidence — October 1, 2019
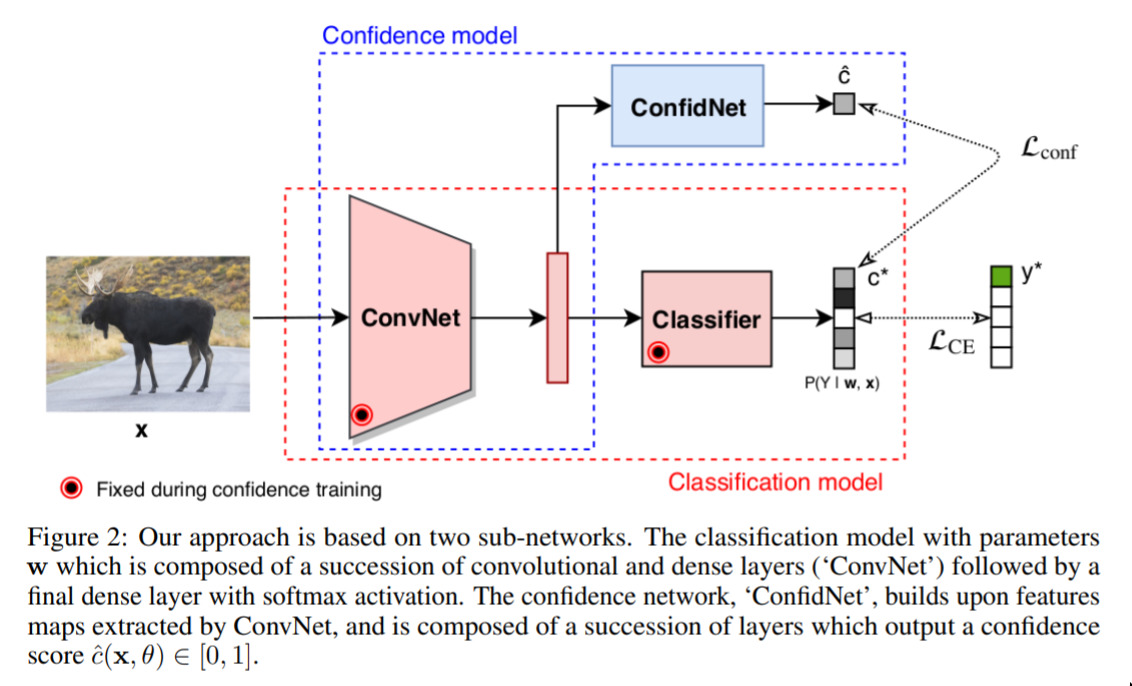
This is topic close to my heart. I’m very interested in thinking about how we interpret the predictions of ML models, and if a model can even give any kind of meaningful confidence prediction at all. This paper attempts to build this idea in. I’m sure it’s not the last word, but it’s a good step in a line of research that I think is very important.
-
Raiders of the Lost Art — September 10, 2019

This is a super neat, practical application that I love. The authors address a neat problem: suppose some canvas has some art has been painted over. Can we recover that painting? Of course, given that some information is lost, we can only go so far, but they neatly use Style Transfer to re-paint the lost painting in the style of the supposed artist. Really cool!
-
Gravity as a Reference for Estimating a Person’s Height from Video — September 5, 2019
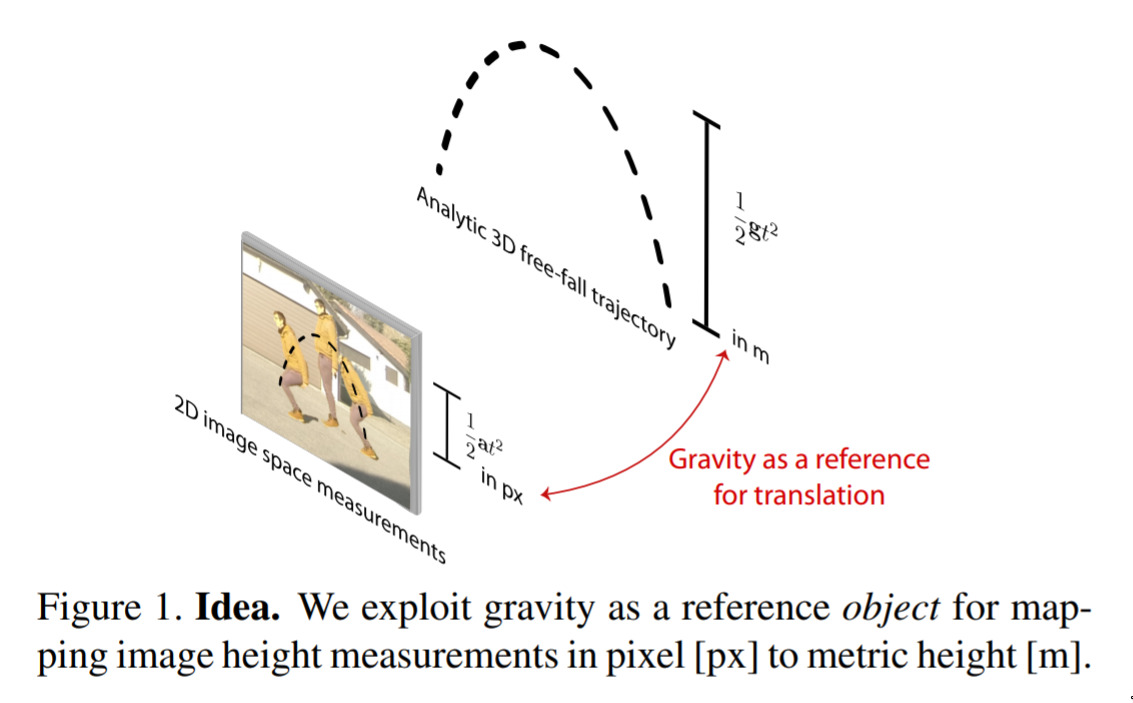
I love this one for the awesome idea they’ve had. They want to solve a reasonable problem - how tall is the person in this photo (here, actually, a video). They’re observation is that if they ask the person to jump, then they can use information about gravity as supporting evidence to estimate the height! It’s such a neat idea.
-
Translating Visual Art into Music — September 3, 2019
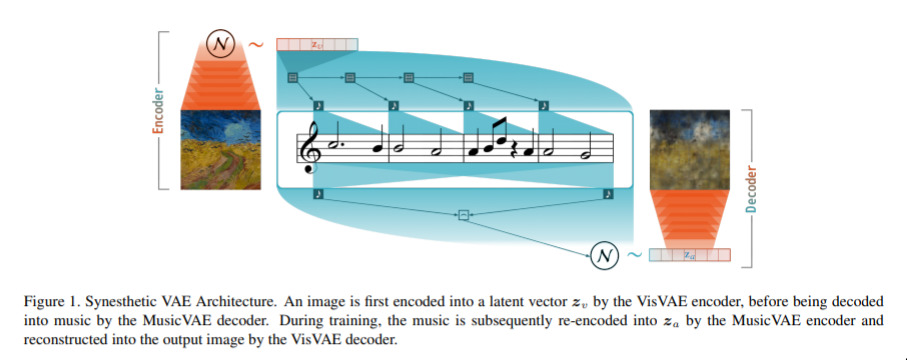
This one is weird and I love it. The idea is to translate a painting, let’s say, into music, so that vision-impaired people can learn to enjoy paintings. This one is fascinating in that it tries to ensure that something like the original image can be reconstructed from the stream of music. They phrase art, then, as an information exchange. Crazy!
-
Enforcing Analytic Constraints in Neural-Networks Emulating Physical Systems — September 3, 2019

Simliar to the “MIPs as a Layer” paper, this one is again about enforcing constraints into neural networks, but here the view is that we want to do this so that it respects the physical constraints of physical systems. As we attempt to solve more Physics problems with deep learning, we’ll see much more of this. I think it’s exciting!
-
Story-oriented Image Selection and Placement — September 2, 2019
This one is a neat and interesting idea. The point is, consider a paragraph of text. What image should accompany that text? It turns out, you can solve this problem by learning what’s in images, and what the text is talking about. I think this is something we’ll probably see more of over the years; aligned content generation, i.e. “this goes with that”.
-
Visual Deprojection — September 1, 2019
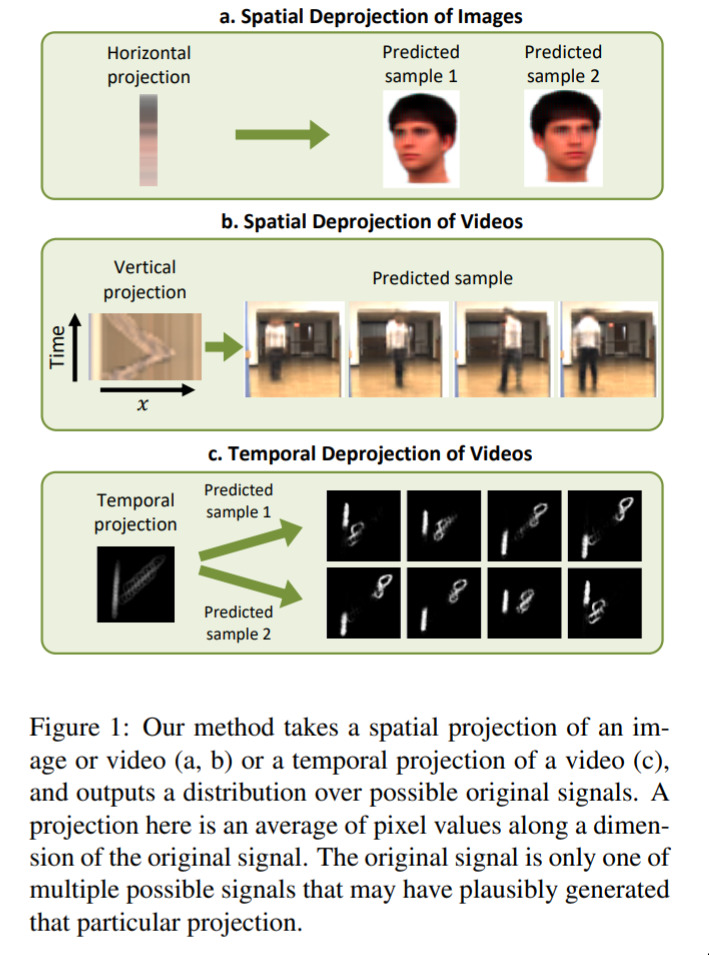
This is a moderately quirky one. The idea is that we take some high-dimensional information (say, 3D) and then project it down to 2D. The question is, how well can we reconstruct the original input? Turns out, pretty well. This idea can be useful when thinking about how to compress high-dimensional data.
-
Real-world Conversational AI for Hotel Bookings — August 27, 2019
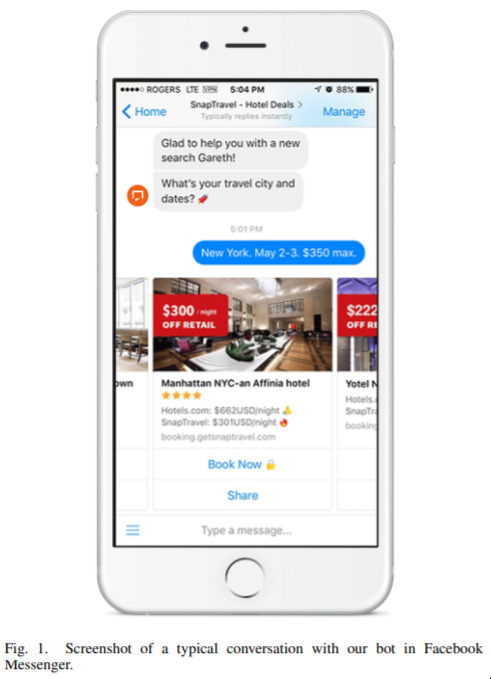
We don’t feature a lot of chatbots here, but I thought this one was interesting because of how real-world focused it is. If you check the paper you’ll see that they have an explicit consideration for when a human should take over a convseration. Furthermore, this is a real system deployed in the real world. Furthermore, they should how they’ve utilised some cutting-edge models (BERT). It’s good to see this kind of real-world design.
-
Physics Informed Data Driven model for Flood Prediction — August 23, 2019
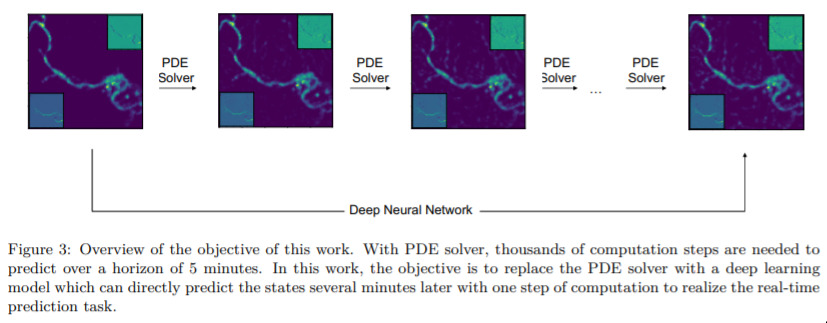
This is one of a series of works that is interested in explicitly incorporating Physics into deep-learning based models. I think these ideas are really interesting and well worth exploring. Here they aim at speeding up computations by combining a GAN with standard simulation tools.
-
Federated Learning — August 21, 2019
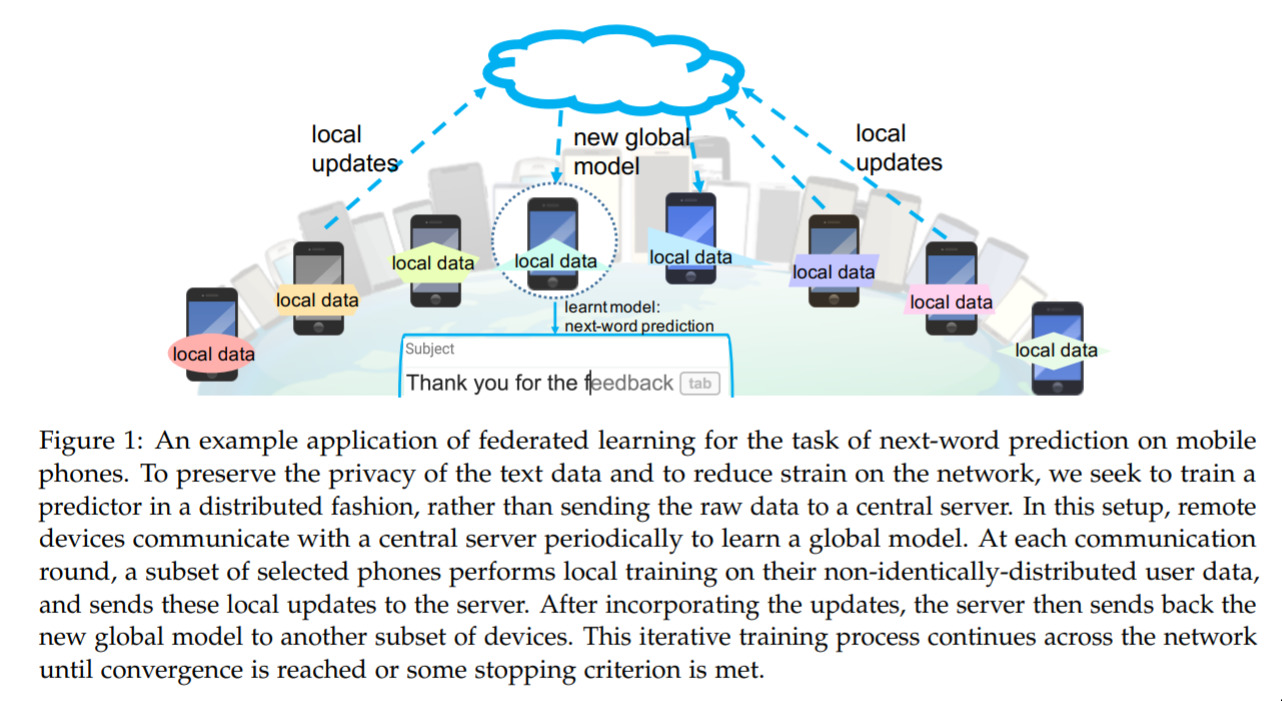
This one is interesting from a real-world/privacy angle. We know that we’re going to see more and more deep learning on phones. And we’re going to have our phones start to adapt to us. But we’d also like to know how to leverage data from other peoples activities, but in a private way. How can we train things in this regime? How should distributed training even work? This paper presents some current research, challenges, and ideas for the future.
-
A Low-Cost, Open-Source Robotic Racecar for Education and Research — August 21, 2019

This is a neat one for those wishing for more car-based deep learning projects. I myself have something similar to this, but with nowhere near the bells and whistles that this one has. This had LiDAR, RGBD camera, and even a collison-indicator! All up, a super cool project, that’s totally open-source!
-
Towards Arbitrary High Fidelity Face Manipulation — August 20, 2019

Every so often I stumble across a paper where, when they show the results, I don’t quite believe them. This is one of those papers. The manipulated photos in this work look so realistic to me that I’m still amazed! Very cool work. They are able to take in single-images, and then richly manipulate them to desired expressions!
-
Deep Sketch-based 3D Hair Modeling — August 20, 2019
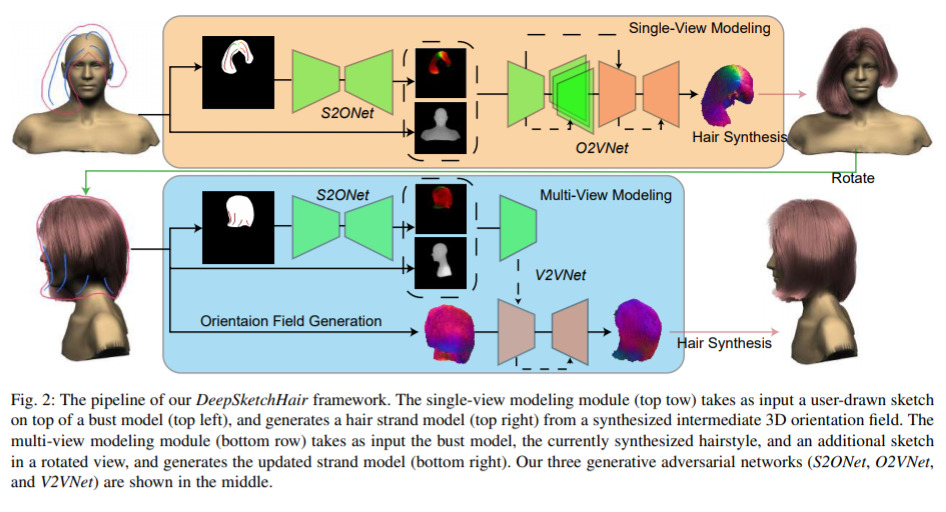
This is one my long-time dreams. I’ve often wanted something to help me generate different haircuts. What this work introduces, is the ability to draw a rough sketch of the hair, and have the model produce a full, rich, 3D model of the hair! Amazing work.
-
Video synthesis of human upper body with realistic face — August 19, 2019

We’re seeing a lot of work like this with the “#DeepFake” meme. The point here is that they’re completely generating (somewhat) arbitrary poses of people sitting at desks, talking. I.e. with generate hand-movements, body movements, head movements, and mouth movements. This work is just yet another that makes a significant contribution to this meme. Expect these fake videos to become better and better, and harder to detect.
-
Learning to Dress 3D People from Images — August 19, 2019
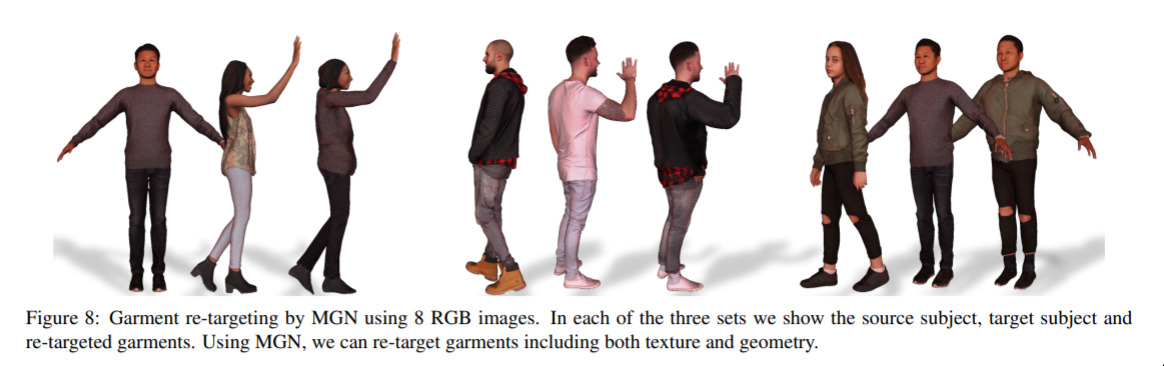
A classic aim of the fashion retailer; this paper introduces some work which lets you clothe a 3D model from 2D images. We will undoubtedly see this kind of work on fashion websites very soon.
-
3D Object Instance Re-Localization — August 16, 2019

This is an odd one but probably important to someone. Suppose that you can compute a 3D object instance segmentation. I.e. you can locate where an object is in 3D. Then, given a different view of the scene, can you find the objects again? This is important, probably, because succeeding at the instance segmentation at arbitrary views of the scene is harder, you might think, then if you use your prior knowledge about the objects positions, having seen them before.
For me this is an interesting work related to the general idea of “temporal coherence”; i.e. using knowledge that we know from a previous timestep at a new timestep.
-
Differentiable Reasoning — August 13, 2019

I really like the ideas of this one. There’s a bit of work going around this idea: contextual knowledge should help us. Here, the formalise this idea that we can do better at classification if we know other things about what we’re trying to classify. In the photo the example is that we can do better a deciding if something is a cushion if we know that it’s at the very least part of a chair.
-
Image Inpainting via Structure-aware Appearance Flow — August 11, 2019

Inpainting is a classic task in computer vision: Given some empty area of an otherwise complete image, can you figure out what should be there? This work is interesting because they realise that “structure” is important when thinking about solving this problem. In other words, you can say things like “This part, and this part should be the same”. It turns out that if they build a network with this consideration baked in, then they can do really well at this problem!
-
Visual Search at Pinterest — August 5, 2019

This is a nice one, as it’s a very production-focused example of how Pinterest deploys different “visual search” capabilities. It’s interesting to see how they set up their training and deployment environments.
-
MaskGAN - Diverse and Interactive Facial Image Manipulation — July 27, 2019

A classic idea of the times; here we have a network that is able to take as input a face, and then modify it according to some simple mask. I.e. you can draw exactly where in the picture you’d like a “smile” to be. They show how they can learn to manipulate many parameters in this way!
-
On the “steerability” of generative adversarial networks — July 16, 2019

This is a cool paper. We’ve seen lots of generative work from “Generative Adversarial Networks (GANs)”. In this work, they explore how “controllable” such networks are. I.e., can we generate a picture of a dog, and then zoom in on it’s face? Can we generate a building and change it from night to day? They perform some investigations in this area, and show that there is lots to be done, but solving these kinds of problems will become very important as we see these generative networks used more widely.
-
Autonomous Driving in the Lung — July 16, 2019
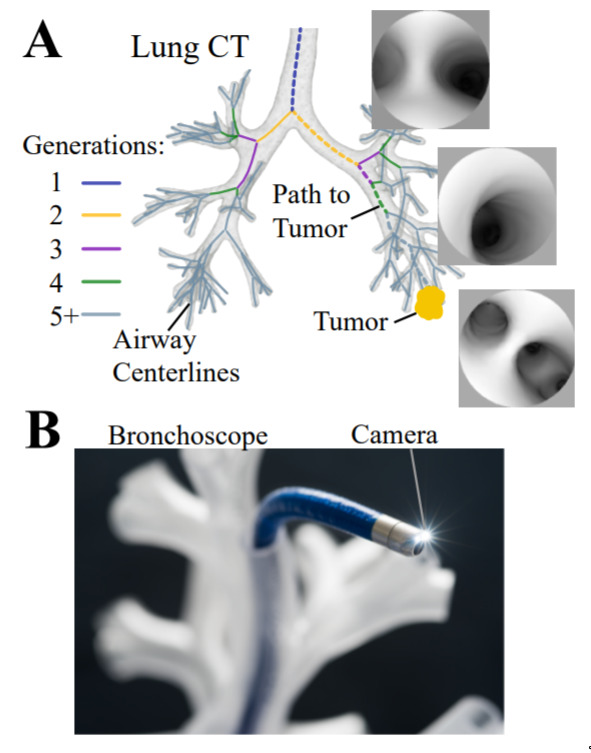
This is some neat work. First, they use data from a patients on medical scan. Then, the learn how to navigate in this rich 3d world from video images. Prety cool!
-
Mixed Integer Program as a Layer — July 12, 2019
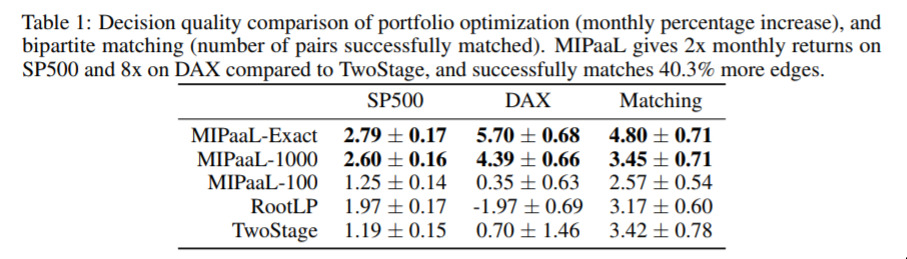
MIPs are close to my heart; and I really enjoy papers that combine many techniques together. This one is interesting because, again, it’s this idea of combining constraints into neural networks, and in particular bringing this information into the optimization of the overall network.
I’m not sure this idea has reached peak popularity yet, and it’s great to see more things being squeezed into the general capability of these deep networks.
-
Learning to Self-Correct from Demonstrations — July 12, 2019
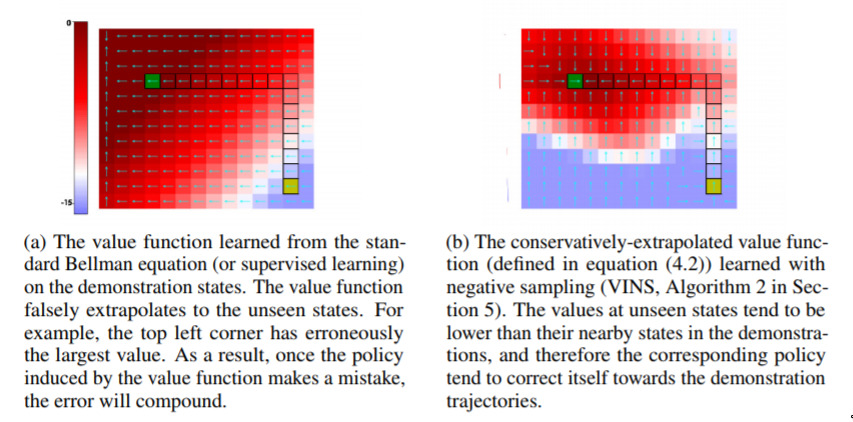
This one is a bit technical, but the main idea here is that they are able to “moderate” how reinforcement-learning networks will extrapolate, when they are learning by example. An analogy would be that, when you watch someone take a sip from a cup, you assume “brilliant, I can drink from any thing that I am holding”, and then you try and drink from a pen, or a book, or such. Here, they introduce the idea that perhaps you should act a bit conservatively in areas where you are unsure, such as holding new things.
-
Hello, It's GPT-2 - How Can I Help You — July 12, 2019

This is an interesting one. They use the now-famous GPT-2 network to help them understand queries from users; they then build a sense of “belief” about what the user wants (in the image you can see the system learning they want a “hotel” that it “expensive” in the “center of town”. Then, from that belief, they generate a text response. This is our usual kind of favourite thing: the combination of many techniques to produce a nice result.
-
Eliminating Forced Work via Satellites — July 12, 2019

This is an amazing application. The researchers train a fairly standard detection network, “resnet”, and train it to detect certain objects in satellite imagery. Here, though, what they are detecting are “brick kilns”; places where there may be forced labour. By helping identify these locations, they can then be referred to the authorities!
This is a beautiful application of deep learning, and the authors note that they are also addressing one of the UNs sustainable development goals!
-
Generative Choreography — July 11, 2019
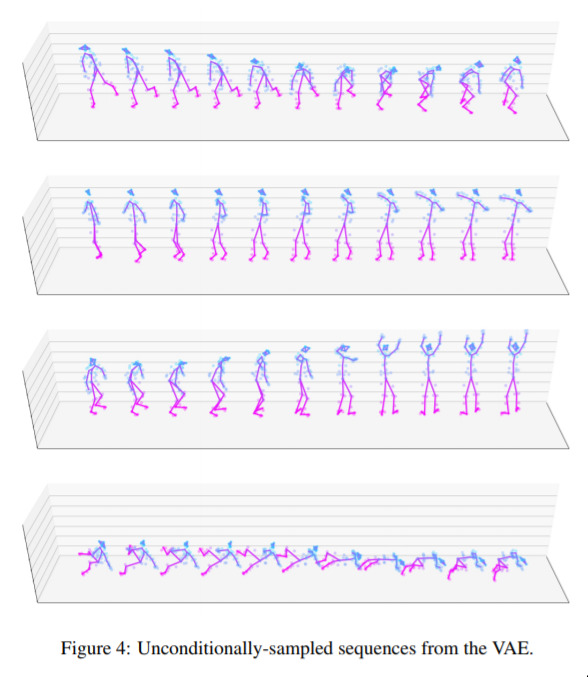
Here the use a standard tool from text processing, the “Long Short-Term Memory (LSTM)” network to watch dance sequences and generate new ones. This is something I’m personally very interested in, and in fact have done work in before! So it’s nice to see some more contributions to this area.
-
Synthetic fruit — July 10, 2019

This is an old idea, and just one example among many. There’s nothing inherently outstanding in this paper, but we just wanted to note the very useful technique of using “fake” (synthetic) data to help solve real-world problems. This is a very useful technique, especially in light of the remarkable abilities of transfer learning to help us adapt to new data.
-
Out-of-Distribution Detection using Generative Models — July 10, 2019
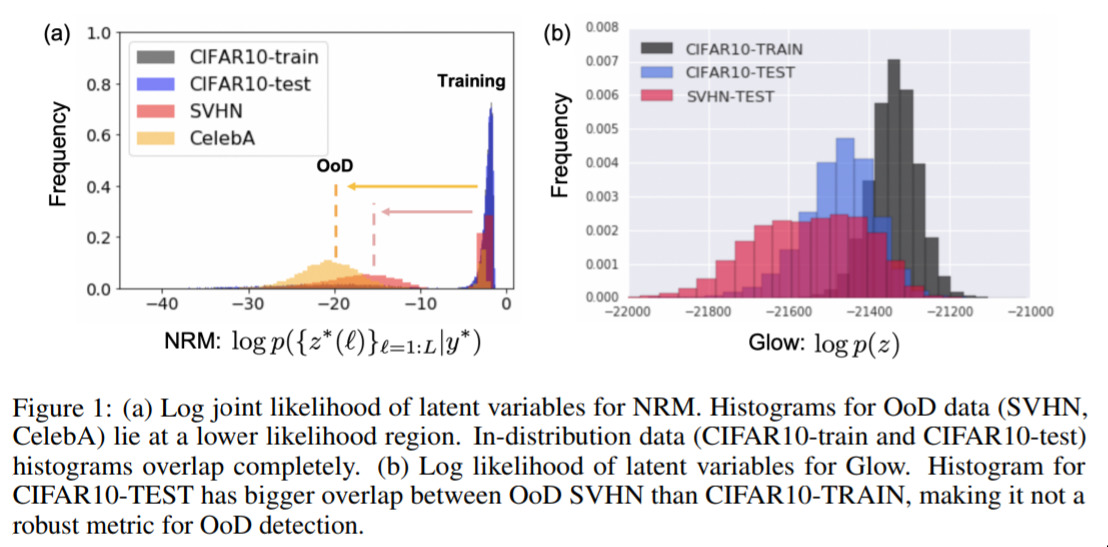
In an old blogpost we discussed the problem of networks making over-confident predictions. This paper focused on over-confidence on images that the network has never seen (i.e. trained on cats and dogs, then very confident that a picture of a boat is a dog).
A classical idea (we saw it in the “Detecting the Unexpected” paper) is that if we think about how well we can reconstruct a given image, that might tell us something about how often our network has seen it; i.e. if it’s “in-dstribution” or not.
This paper notes that one problem with that idea is that if the thing we’re looking at is “simple” (technically, has “small variance”), then because the generative models are powerful, they might still do a good job.
The approach they provide in the paper is to use a different kind of generative network, the so-called “Neural Rendering Model (NRM)”, to do the image generation, and that this new technique just happens to be better at being informative when the data is from a set the network has never seen.
The picture above shows that the NRM-approach does quite a good job of seperating between images the network has seen and hasn’t seen.
This is a bit of a technical result, but it’s a crucially important area of research for networks that are going to be used in the real world.
-
Learning to understand videos for answering questions — July 10, 2019

Videos are becoming increasingly prolific on the internet. Naturally, then, it makes sense that researchers are spending time trying to understand them. One particular area of research is so-called “Visual queastion-answering”. The point is to train a network to be able to watch a video, then answer questions (via text) about what happened in the video. Some examples are provided in the image above.
This work introduces a nice idea to this area, one that we’re seeing frequently on the showreel, namely: building up a rich representation first, and then using that representation to further refine answers. This should be a bit similar, conceptually, to the “Scene Graph” work, for example.
It’s also neat that the researchers are from Deakin!
-
What-If ... We could interactively understand ML Models? — July 9, 2019
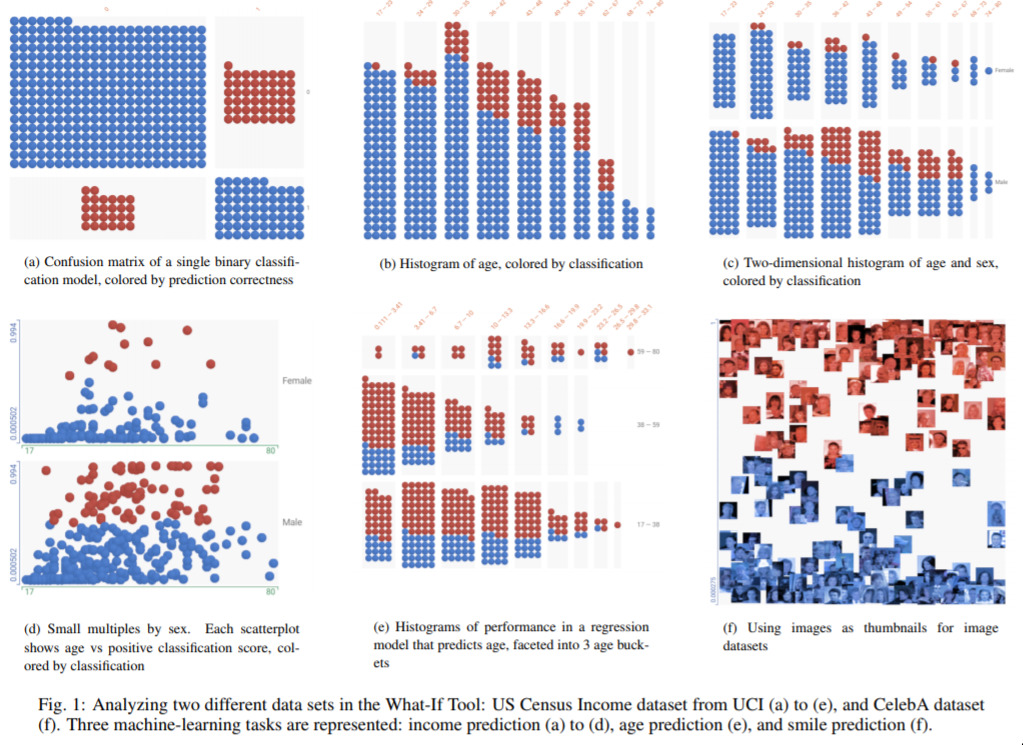
This is some software that Google put out a few years ago under a different name (it was called “facets”). This specific tool I’m not so convinced on, but it’s a very good attempt to tackle a very important idea — how bias and decision-making can be understood interactively.
-
Machine Learning for Side Channel Attacks — July 9, 2019
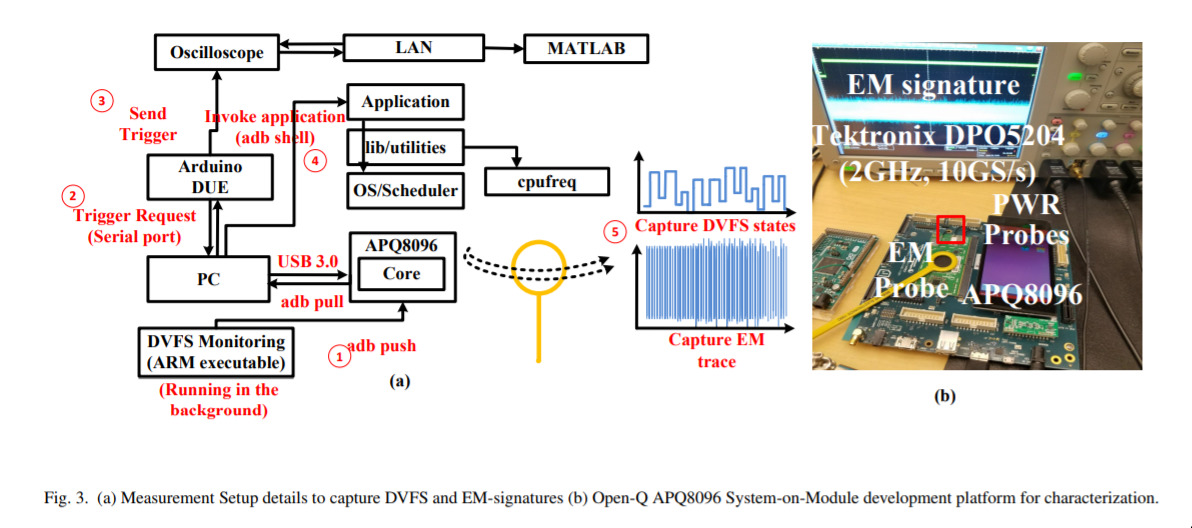
This is a quirky one, but it’s kind of “flag-planting” in the ML/Security world. For years, security researchers have spent time finding what they call “side-channel” attacks. An example is, say, listening to the soup that someone makes when typing, and from that sound, working out what they are typing. It’s called “side-channel” because it’s not, say, capturing the keystrokes via the computer, it’s via an additional “channel”.
The main point of this paper is that they’re applying standard ML techniques, in particular in regards to voltage, and are able to make an estimate of which applications are running on a given piece of hardware. This might not sound super useful as it is, but, as always in the security world, there’s much more juice to be squeezed here.
This will definitely be a space to watch in the security space - bringing in AI techniques to enhance our offensive security capabilities!
-
Designing User Interfaces that Allow Everyone to Contribute to AI Safety — July 9, 2019
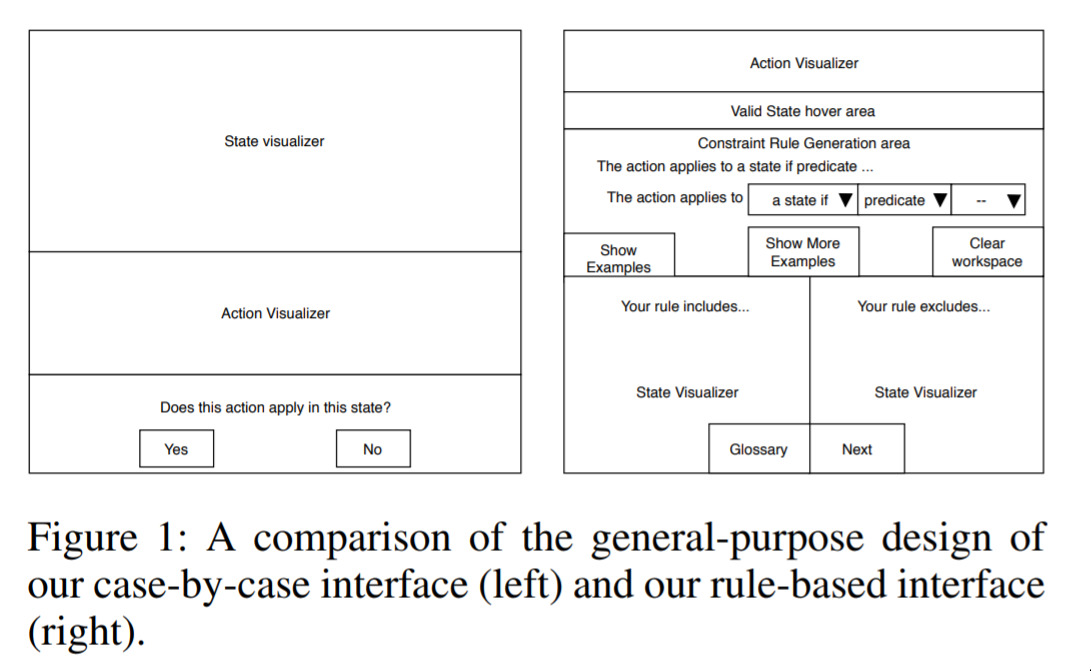
Improving the situation around AI Ethics is strongly on our agenda at the Braneshop. This paper highlights an interesting situation: suppose you have people who want to provide feedback to some decision making process; what should the interface they use look like?
Here they explore a potential design that allows people to see the impact of their actions in a variety of ways.
This won’t be the last word on the matter, but it’s a nice contribution to the field, and hopefully pushes people to think very hard about this problem.
This is one bit of work in a growing field we refer to as “The UX of AI”. This will definitely be a huge area over the coming years.
-
Linking Art through Human Poses — July 8, 2019

This one is cool for the kind of neat technique it demonstrates. They use a pose network (something that just looks at an image of a person, say, and estimates what their skeleton looks like; i.e. it tries to guess some straight lines that connect their arms and legs and such) to connect different artworks. It’s a neat application of what is becoming a standard technique.
-
Estimating travel time without roads — July 8, 2019
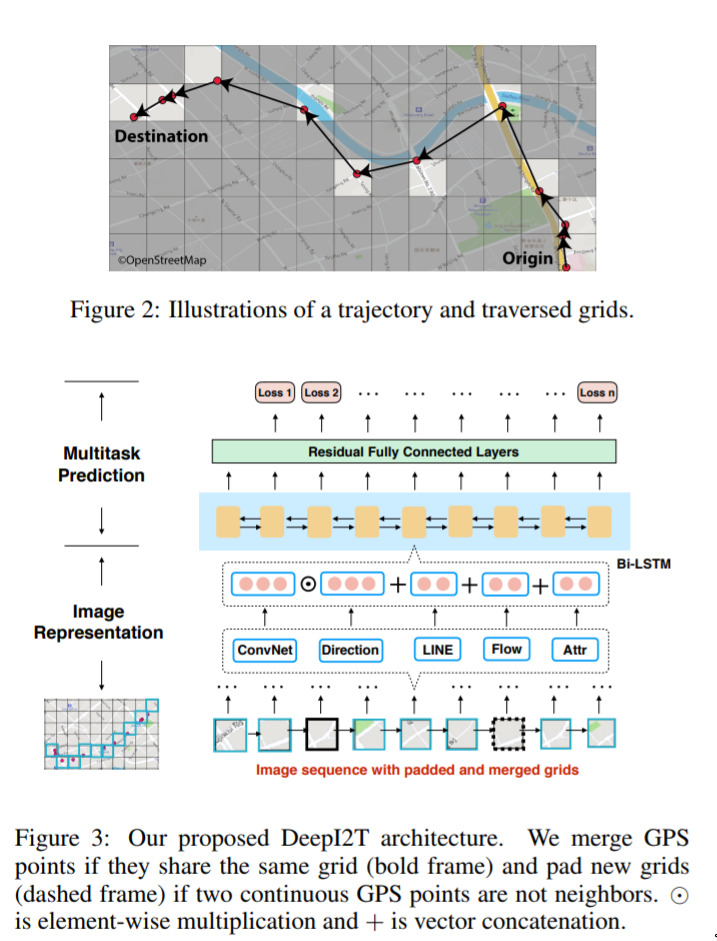
Again, a neat idea applied well. In this paper they suppose that, in fact, we don’t need detailed road networks to do reasonably well at estimating travel time. We just need to get a vague feeling for the kinds of areas we’ll be travelling though (i.e. highway, commercial, residential, country, park, urban, etc). They make these ideas precise and get some great results!
-
Action Recognition from Poses — July 8, 2019

A pretty standard, but useful, technique that uses a kind of multi-stage process to: 1) compute the pose, 2) then from the a series of these poses, ver time, work out what “action” people are performing. Specifically here they focus on people going past train ticket machines in various ways, but the application is general.
-
Albatrosses from Space — July 3, 2019

A really nice scientific application of deep learning; and something that maybe any reasonable person would not assume is possible right now. We like this one because it’s the overlap of modern deep learning techniques to old (but important!) problems of tracking animal movements for conservation reasons.
-
AI for Economic Uplift of Handicraft — May 31, 2019

While this one isn’t strictly using deep learning, it does use some classical machine learning techniques. But the reason we consider it particularly cool, is because the authors actually took their system “to the streets”, as it were, and verified that using the new design processes helped the artisans sell more items!
-
Attacking person-identification with patches — April 18, 2019

The game in this one is - can we make a picture, that can be printed and held in front of us, that will fool a person-detector? Yes, it turns out.
This is refered to as an “adversarial” attack, and they have gained a lot of attention recently. This one in particular is interesting because they attack a standard person-detector (so-called “Yolo”) and the image they use is “local” and “printable”. There had been a few results in this area, but nothing attacking person detectors.
In the research world, we’re seeing work on both fronts. There are a lot of work on how to do more of these, and make them more robust, and likewise there is a lot of work on how to make classifiers and detectors less vulnerable to such attacks. Who will win? It’s not clear. I’d put my money on it always being possible to make such attacks, given enough information on the classifier. But, the cost of such attacks will rise significantly, making it unfeasible for most of us.
-
Detecting the Unexpected — April 16, 2019

This is a really neat and important idea. The application here is in self-driving cars, but the central idea is very general. The main point is, if we’ve trained a network to detect certain classes of thing (“car”, “road”, “person”, “truck”) then, if it sees something completely unexpected, (“goose”), what will it predict? Depending on how you set up the network, it will predict one of the known classes. This work is about quantifying how confident the network should feel about such prediction. Their idea is to ask the network to think about how well it can reconstrut the thing it thought it saw. If it finds it hard, then that indicates that the thing it saw is moderately unknown to it, and so it shouldn’t be confident. As we have more AI out in real life making decisions, quantifying uncertainty will become increasingly important.
-
Expressive 3D Body Capture from a Single Image — April 11, 2019

More and more we’re seeing deep learning tackle rich reconstruction problems from simple inputs. This is a classic of the genre. As humans, we can easily imagine the 3D structure of the person in the photo; and it turns out now deep learning can do the same, via the techniques in this paper. It’s very impressive work, and is applicable for those people wishing to capture this information without a complicated set up of a 3D body scanner. As usual, the typical applications will be in retail, but maybe also augmented-reality and other such fun things. As is the case with all these body-pose-related papers, they use an underlying pose network and build on top of it’s outputs. This is also a central and important topic in modern AI: building up rich and strong capabilities by combining different techniques.
-
Extreme Image Compression — April 8, 2019

A natural thought would be that if we know a lot about the thing we’re trying to compress, we can do a better job. Standard compression algorithms are general-purpose, and as such, there is probably room to improve. This is the observation and work in this paper: They learn a compression function for a specific set of data, and they do really well! Probably not suitable for most of us, but you can be sure the big data storage providers will be working on these kinds of techniques into the future.
If we wanted to be trendy we could summarise this as “big data makes small data”.
-
Can a Robot Become a Movie Director? — April 5, 2019

The main point here is that if we’re interested in determining where to point a drone while filming some scene, it might be hard, because the director would need to be able to somehow see everything, while the drone is flying. This paper proposes that perhaps thee could be a method to have the drone know where to look.
-
Image2StyleGan - aka Ryan Obama aka Oprah Johansson — April 5, 2019

One of the most exciting areas of AI is the generative/creative opportunities. And in this area, something people are always fascinated by is the exploring the “space” of images; i.e here are all the photos of people, but what does a person who is “halfway between these two people” look like? This paper works on that problem, and produces some very cool looking people such as Ryan Obama, Oprah Johansson and Hugh de Niro. Notably, in this paper it seems like it doesn’t work so well for abstract/non-person style photos; but that’s probably due to the data, and not a general problem.
-
Learning how music and images relate — March 30, 2019
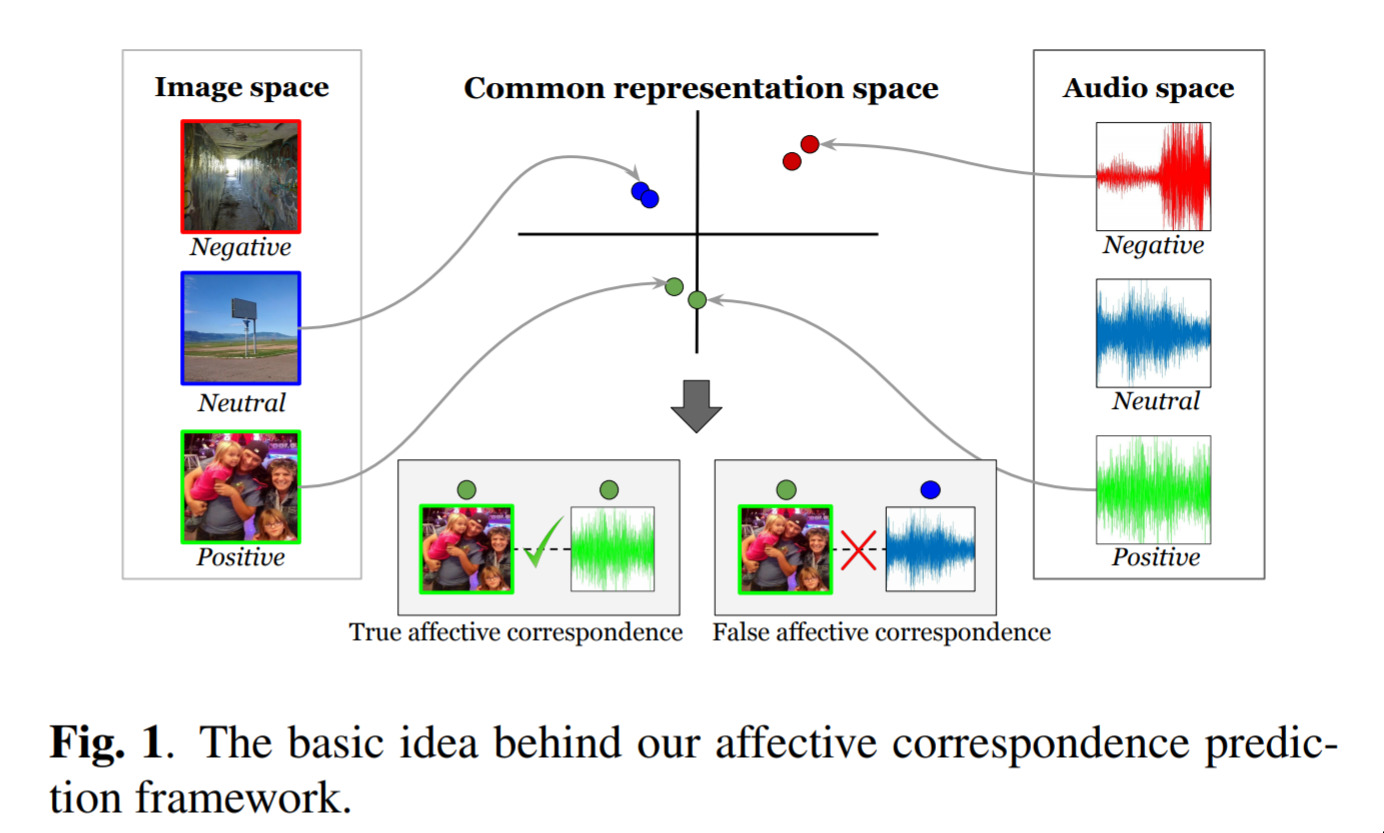
This result is nice because it’s using a concept that we think is so important, we’ve made it a central part of our technical workshop: the autoencoder.
In this work they map images and music into the same “space” (i.e. points on the graph in the picture), and in-so-doing, they can learn when images and music are related! Nice, simple, and useful!
-
Detecting people using only WiFi — March 30, 2019
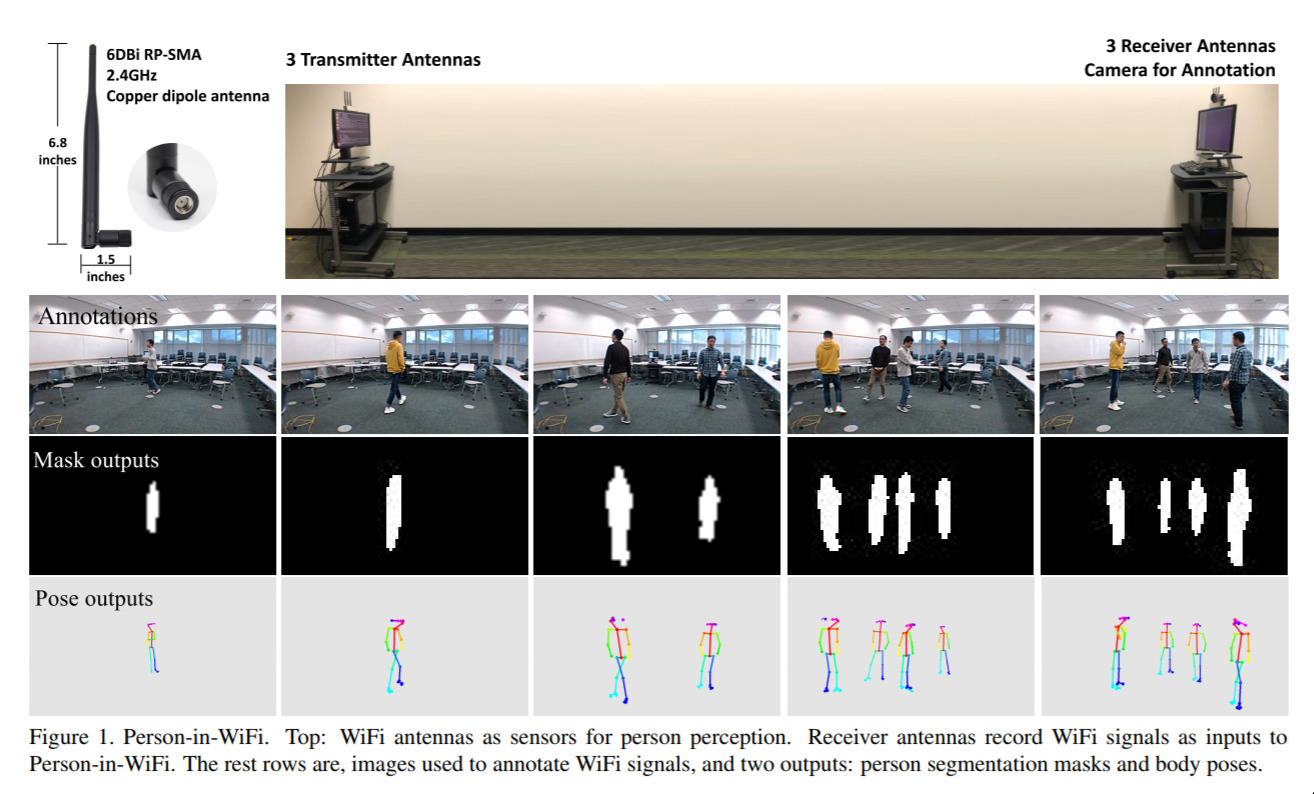
This is an interesting one. WiFi is everywhere; and probably a reasonable person wouldn’t assume they could be tracked (down to estimates of where they are walking, and the overall pose of their body) if there isn’t a camera around. But it turns out that this data actually can be gathered in (an ideal) WiFi set up. That is, the pose of people was determined without a camera; using only WiFi signals. No doubt this field - sensing human activity through non-camera based sensors - will continue to grow.
-
Face Synthesis from a Single Image — March 26, 2019

Ignoring the specific contributions, this is a conceptually simple paper; but the results look amazing. The idea is: can we find a 3D model from a single image? And how much detail can it capture?
Turns out, heaps of detail! They introduce some nice techniques for modelling the facial features and such, but the main thing I like are the results.
-
Unconstrained Ear Recognition — March 11, 2019
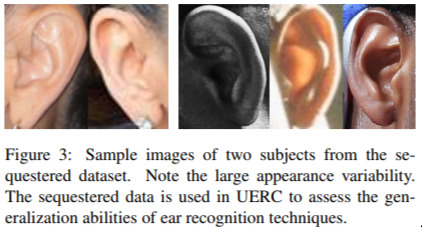
Trust no-one. If you think covering your face is enough to stop people from detecting who you are, you’re wrong. It turns out it’s possible to identify people from their ears. Why would anyone want to do this? Who knows. But it’s happening!
-
Finding small objects in a large scene — February 6, 2019

Satellite imagery is a hot topic. There’s been many stories of people using such imagery to gain competitive advantage in many ways; from estimating the number of sales at department stores, to prediction crop yield.
This paper in particular is very neat because they discuss a network that allows them to compute fine-grained information — colour, position, and angle of cars — in very large satellite photos.
This is really an impressive result.
-
What Is It Like Down There — June 13, 2018
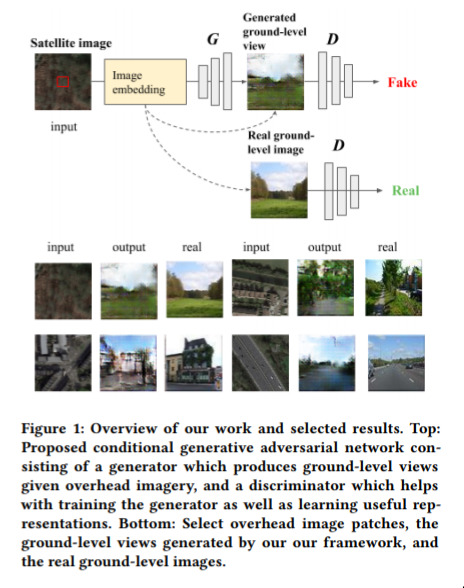
This is already a classic of the generative genre. They take a satellite photo, and then use GANs to work out what that particular region woud look like if viewed from the ground.
It’s amusing to me because it’s moderately well-posed; i.e. there is definitely the data present to make some kind of guess, but getting to the ground truth is kind of “obviously” impossible.
Even under such contraints, they do pretty well! And, as we most of this generative work, this is something that will only get better.
-
Image Generation from Scene Graphs — April 4, 2018
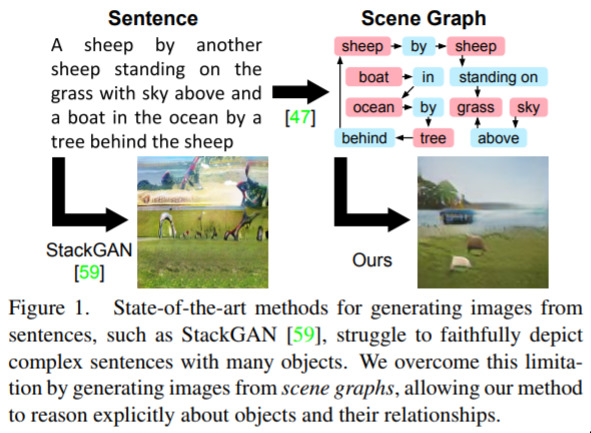
Work from the famous Fei Fei Li, this is a very neat idea. There’s been some famous networks (“StackGAN”) that are able to generate pictures from text. But, they fail when you want to generate a complicated and unfamiliar scene. Humans, of course, can “dis-entangle” different concepts when thinking of complicated scenes, such as “a cat waiting to catch the train”. Even if we haven’t seen this exact thing before, we can easily imagine it, because we know how the things look, independently. The contribution in this work is the same idea, for neural networks, and they achieve awesome results! We can definitely expect significant improvements in this area, over the coming years.
-
Women also Snowboard — March 26, 2018

This is a famous and interesting paper. They identify a common problem in so-called “captioning” networks: namely, they can be right for the wrong reasons. In the photo, we see that a network guesed it was a man sitting at a computer; but it only spent time “looking” at the computer to work this out. In other words, a computer was strongly correlated with the photo being of “a man at the computer” in the training data. In this paper they introduce some techniques to deal with this problem. Basically, their idea is that we can penalise the network for thinking about gender when no gender information is present, and reward it for thinking about gender when it is apparent. Furthermore, their approach is generally useful for other models and situations.
We can expect more technical results in this area to be implemented alongside the social techniques (i.e. having more diverse people involved in the building of AI systems).
-
Trying clothes on, virtually — November 22, 2017

This is a great example of attempting to apply AI in the real world. The problem here is the typical online-shopping problem: Here’s a thing that maybe I want to buy; but how would it look on me? This paper attempts to solve that problem by using pose information. It does a pretty good job for photos that are “simple” (i.e. model on a white wall), and does a reasonable, but not great, job on what is referred to as photos “in the wild” — just photos from everyday life; inside or outside. Over the years we can expect to see this kind of technology hit on-line retailers.
-
Priming Neural Networks — November 16, 2017

This is a fun one. First, try and find “something” in the photo (it’s normal-sized; and you’ll know it when you see it).
…
Did you find anything?
Now, try searching for: a cat (highlight this section of text to see it). Can you find it now that I’ve told you what to look for? Even if you can’t, it turns out that neural networks can. I think this is a really neat idea - priming a network to help it know what it’s trying to do.
-
Style Transfer in Come Swim — January 19, 2017

This is a landmark paper for a few reasons. First of all, it’s co-authored by a movie star; secondly it’s an application of the famous “style transfer” algorithm to a short film, and importantly that put a significant amount of work into making sure that the sylistic quality of the style transfer is high; which you don’t typically see. It’s a really interesting collaboration between the researchers and the film industry. I’m sure we’ll see a lot more like this over the years!
-
Understanding and Predicting Visual Humour — December 14, 2015
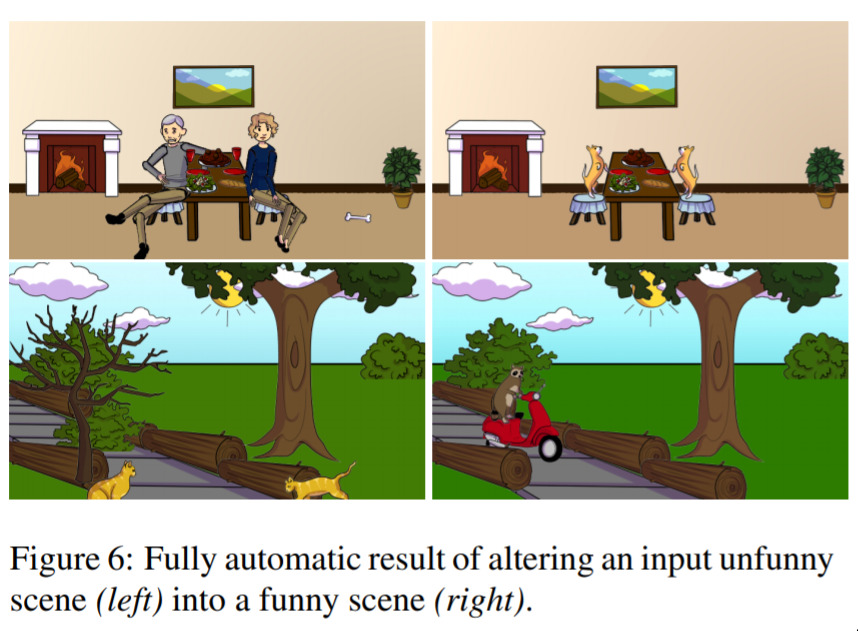
Easily Noon’s favourite paper of 2015. In life we face many problems. One of them is, given some non-funny situation, how can we make it funny? Naively one might think computers can’t begin to attemp to solve this problem. One would be wrong. Consider the top row of this image. Two people having dinner. Very unfunny. Two dogs having dinner at a dinner table? Hilarious. Likewise, cats in a park? Unfunny. A racoon riding a scooter in the same park? Brilliant.
This network was trained on data generated by humans who took specific scenes and adjusted them to make them funny.
We’re not totally sure where we’ll see more applications of this work, but we love it.

You can find a bunch of other cool papers, that I never got the chance to write up, over here.
